#1 SciTech Thread

mounting remote disks to use from application code is kinda super meh, so instead of that I thought of an http service to handle writes/deletes/links and a library to use it from code.
like S3 but local wdythink rubber duckie
but also not complicated and slow like miniohalso I kind of want to move to non-raid to keep things max simple (and to unlock unlimited cloud backup) but how should I then handle expansion? my current thinking is adding a "bucket" argument to requests where each disk is a bucket so when one is starting to get full switch to a new bucket is it too simple even holy

>remote disks to use from application code
what application?
>like S3 but local
local FS? or your own server?
>also I kind of want to move to non-raid to keep things max simple
without RAID it will take more time to restore data if one disk suddenly goes down. with RAID you just change disk and everything continues to work
>my current thinking is adding a "bucket" argument to requests where each disk is a bucket so when one is starting to get full switch to a new bucket
yeah sounds simple enough
>unlock unlimited cloud backup
is it even a thing? I read a bit of https://forum.rclone.org/t/unlimited-alternatives-to-google-drive-what-are-the-options/36529 recently and there're almost no good options
>not complicated and slow like minioh
first time I hear about it
>High Performance Object Storage
https://github.com/minio/minio/issues/10733
>storing objects as files on FS


oh hey rubber duckie
>what application?
youtube and image archivers. kpop!
>local FS? or your own server?
yeah the computer with the disks would also host the http service that would then write the files to disk. a poor mane's
limited bucket sizeobjekt storage>without RAID it will take more time to restore data if one disk suddenly goes down
it's just kpop so doesn't really matterino
>is it even a thing?
looks like amazon drive is gone but backblazeh is still there
a simple 10 dollarinos a month to backup a single computer and it's drives

duckie yeah i tried it for a while but it was very unlit
small notes for the duck from last night
smb/nfs mounted disks:
>unnecessary file permission memes
>question mark whether its actually connected or if i'm writing to the unmounted mount point dir
>if application is dockerized prepare another layer of mounting and file permission memes
>often an expensive, high intelligence raid setup like a duna
minioh:
>performance slow
>files not stored as real files but split into weird pieces
>no softlinks
a small http service that writes things onto disks so you only need to send a post request to an ip address:
>comfy af
>small and cute like a yuna

>yeah the computer with the disks would also host the http service that would then write the files to disk. a poor mane's limited bucket size objekt storage
can't you use something even simpler like SFTP then?
>youtube and image archivers. kpop!
unraid might come handy because of simple server management & raid 4
>but backblazeh is still there
backblaze backup is only for windows/macos and with a lot of limitations like not syncing external drives. no free lunch
backblaze b2 is pretty expensive per TB
I would recommend OneDrive: 6TB per family account and you can buy keys for ~$56/year, so it's about $0.8/TB/month. that's what I personally use for off-site backups
I can't see how HTTP service with API is simpler than SFTP
>mini ooohhhh
also I don't understand why do you need some HTTP server at all
if you have computer with connected disks, then just ran archiver program from that computer and everything is just a local file

>but also not complicated and slow like minioh
what about MongoDB GridFS
found discussion about some guy using it for >150TB >1B of objects on XFS
overkill for kpop tho, you probably won't find 1B of pics of kpops in the whole net


yeah computer needs to be win/mac with local disks to enable unlimited backup, but I also dont want to code against those platforms so
>6TB per family account
my yt collection is already 8tb although I'm looking into slimming that down with better review tools so I could move fully onto SSD
>SFTP
cool
although I don't want to cd mkdir rmdir etc on client side so I would have to write a wrapper. but then I might as well write the 200 lines of handling server side to make client library as simple as possible

>GridFS divides a file into chunks of 255 kB with the exception of the last chunk
looks like another minio, too fancy for me dumb brain

how is rubber duckie so smart

>my yt collection is already 8tb
you can make several accounts
tho I'm not sure you need off-site for yt archive, seems like not so important. might just use separate computer for backup in a different room for safety
>on client side so I would have to write a wrapper
>server side
do you have multiple computers? why do you split archiving into client/server?
seems like you will need those if you have millions of small files
if your files are big then normal FS is better
I'm not a duckie
https://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis/
>Best used: If you want something Dynamo-like data storage, but no way you're gonna deal with the bloat and complexity. If you need very good single-site scalability, availability and fault-tolerance, but you're ready to pay for multi-site replication.
oh Riak seems interesting for distributed blob storage of files
oh no, seems ded
here are more links:
https://news.ycombinator.com/item?id=12392081
https://news.ycombinator.com/item?id=16627370
maybe Ceph is ok

>why do you split archiving into client/server? do you have multiple computers?
oh I just mean the server part of the local objekt storage versus client library I would use in my archiver code.
but yeah I currently have the computer I use for computer stuff, the home server that has a bunch of VMs on it, and a nas with spinning disks
. but I'm thinking of replacing the nas with a regular ol' computer with SSDsthe nas has a one disk redundancy so I guess that's something, but it would be too expensive to backup offsite
I tried minio for some time but hated it it's so slow and because of the chunking backing it up would mean running some slow bottom command to get the files back into real files
surely regular old SSDs can handle even millions of images if I don't put them all into a single directory
>tho I'm not sure you need off-site for yt archive, seems like not so important
it's something I've also thought about. going no-redundancy for youtube and only really backing up the videos that return 404 since everything else can be redownloaded

>and a nas with spinning disks . but I'm thinking of replacing the nas with a regular ol' computer with SSDs
can't you run archiver (I guess yt-dlp) on NAS? and all your files will be available locally, no need for client/server
>I tried minio for some time but hated it it's so slow
I read not very good reviews about it, seems a bit toyish. other solutions like Ceph should be more mature but need to google more, maybe there's even something better
tho in your case all of that is definitely overkill. I was just having some fun looking into that stuff
>surely regular old SSDs can handle even millions of images if I don't put them all into a single directory
it's not about physical disk, it's about particular FS implementation you use
millions seem ok (for modern FS) if splitted into ~1-5k per directory yeah (but there's no definitive answer on the web about performance penalties)
but billions could be too much
also with FS you need to implement sharding/replication manually
>going no-redundancy for youtube
that's what I'm doing
but I would rather do on-site backup of all data to separate computer and off-site only important if I had spare computer and more disks
>As expected from the common wisdom, objects smaller than 256K are best stored in a database while objects larger than 1M are best stored in the filesystem.

>can't you run archiver (I guess yt-dlp) on NAS?
initially I did, don't remember i moved it off i guess it was too slow
(very low powered synologhy)and also i needed a more complete vpn/proxy solution>millions seem ok (for modern FS) if splitted into ~1-5k per directory yeah
average filesize of images I've downloaded is 720K

>i moved it off i guess it was too slow (very low powered synologhy)
but yt-dlp shouldn't be CPU-intensive, it basically just dumps data from TCP stream to disk even tho it's HTTPS still should be very fast, faster than disk speed
or maybe connect disks from synology to server with VMs?
>average filesize of images I've downloaded is 720K
how many photos do you have?

https://lwn.net/Articles/400629/
https://events.static.linuxfound.org/slides/2010/linuxcon2010_wheeler.pdf
https://stackoverflow.com/questions/14925791/difference-between-object-storage-and-file-storage
good building

beauty type kpops have a more oval head while cute type are more round
science? or just my head canon
>I tried minio for some time but hated it it's so slow and because of the chunking backing it up would mean running some slow bottom command to get the files back into real files
minio is basically object storage abstraction over FS
>On the other hand, MinIO seems to store each object in a directory and two files. So the overhead is even higher.
the only use case is replication and data redundancy but with low performance for basic tasks it seems uselless
if you have billions of small files and file system isn't an option then something like Ceph seems a better option
or if you don't want to replicate files by yourself, Ceph has automatic data redundancy too
tho in case of single server it seems easier just to backup all files instead of those complicated erasure coding schemes like in Minio/Ceph

true maybe I messed around with something else
>backing it up would mean running some slow bottom command to get the files back into real files
not necessary btw, you can just backup the minio's data directory, all your data is stored there
also around 100k fotos but it's a mess currently hehe need to figure out a better search setup using tags and maybe face recognition if i'm able
lol 100k is not a lot, why did you even look into minio

simplest option of all the local S3 thingies I could run in syno
yeah but you don't need object storage for 100k files

true I'm currently writing a babby's first objekt storage server but with real files instead of chunks
fn upload(UploadArgs { key, data }: UploadArgs) -> Result<()> { std::fs::create_dir_all(key.parent().unwrap())?; let mut temp = NamedTempFile::new()?; temp.write_all(data)?; std::fs::rename(temp, key)?; Ok(()) }

>Rust
moved docker.img from vDisk to folder because I think it was wearing my SSD
fucking temporary useless files that are written to disk for some stupid reason
What programming language should I learn in 2024 for employment?



is this something i need to worry about if not using unraid
i'm 4 btw
prompting LLMs like chatgpt to program for you?
other than that idk i'll let smart-nim to answer
>i need to worry about if not using unraid
I think no, you probably have /tmp as tmpfs already. in unraid docker setup is a bit weird, via additional btrfs FS mounted as loop .img and a lot of containers write logs to SSD
might run
#!/bin/bash date=$(date +'%Y-%m-%d %H:%M') wear=$(smartctl -A /dev/device | awk '/Total_LBAs_Written/{printf "%.3f %d", $10/2/1024/1024, $10}') echo "${date} ${wear}"like every day for checking total TBW (GBW in this case)
I'm running it now with inotifywait to check writes and nothing writes anymore except cron tasks I set
>i'm 4 btw
4 years old?
what OS is installed on your VM server though?
dunno, you will probably need to learn many anyway, it's not hard when you know few
might start with Python

windows for that hyper-v comfy
although virt-manager also looks good so might switch to debian at some point
>windows
>virt-manager
there's also GUI for VM management in unraid
https://superuser.com/a/1557449
>BTRFS has a much higher overhead, regarding sector writes, than XFS and EXT2/3/4
uh huh
https://unraid.net/zfs-pools-rc3
ZFS-nim seems good, much better than stupid BTRFS and a simple XFS

fancy
i'm too good at breaking stuff to dare go for it but it looks like a way better synologyos
yeah, it's pretty nice, although have its own issues
just moved my cache pool to zfs, all migration workflow worked very nice
but now I'm thinking about XFS vs ZFS on main array
and ZFS + BTRFS docker img vs ZFS + docker directory vs BTRFS + docker directory
on cache pool
but I think I don't like BTRFS at all but ZFS + docker directory also have its own problem
too many options


https://www.reddit.com/r/DataHoarder/comments/13a0dvr/help_me_store_1_billion_images_advice_needed/

1 billion imageru served from home server huh
cool project
and they didn't recommend him anything better than FS
this is sort of highload case, I guess you won't find much in simple discussions and hyped open source, need to write by yourself or experiment a lot
>I know though that making (uncompressed) tarballs of small files, then storing indexes into these tarballs on fast storage (maybe your database) would help though, I did that in one project. Alternatively, just get rid of the file system (crazy, I know), and write your tarballs directly on block storage. This is a viable choice only if your dataset doesn't change, obviously. I wasn't that crazy though.
oh, I know a highload project which does that
seems like a good idea to minimize IOPS requirement
https://static.usenix.org/event/osdi10/tech/full_papers/Beaver.pdf
oh, facebook does the same
giant flat files with photos placed at offsets and index file to find them
but I didn't hear about open source implementations of that architecture
>but I didn't hear about open source implementations of that architecture
https://github.com/miku/haystack
https://github.com/seaweedfs/seaweedfs
>SeaweedFS started by implementing Facebook's Haystack design paper
problem solved!

billions of files huh
maybe open up some 60fps fancams, hit alt+s and let it burn


babbys first face detection
but hwere i now put this bad boy supposedly i need to create a mystery embeddings vector that contain the absolute essence of yeoni
>embeddings vector
yeah, but it's not very precise
better to download 1B pics of kpops and train by yourself
Which Linux is best for desktop now?
dunno
Ubuntu is a bit stupid with rolling because you always have outdated software or need to use snaps. but it means you have some amount of outdated base packages and some are new and there's 2 ways to install something. not very elegant
in Arch something will always break
Fedora dunno, seems too experimental
Ubuntu-based doesn't seem better than Ubuntu itself, same as with Debian
Manjaro maybe?
or maybe there's some new hyped distro, haven't looked into it for a while because I don't have that problem anymore

how about Windows + WSL?
https://www.reddit.com/r/MLQuestions/comments/1703eit/creating_embeddings_for_1_billion_images_need/

>Creating embeddings for 1 BILLION images
the absolute madman
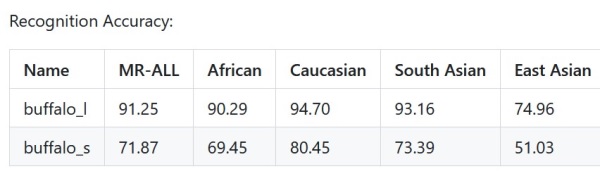
where to find good model if i can't train
dunno, maybe naver has some
it should be trained on asians I believe
>caucasian 94.70
>east asian 74.96
>I have a billion images I need to create embeddings for which are stored on 100tb of flash I have in my homelab. I am using mongo to hold a reference to each locally stored image
so how do you think he did it in the end, sounds like a path to a regular ol file to me
yeah, seems like it
but storing and serving are different tasks, it's ok if it's a bit slow when you just train network on those files, training will be slower anyway
just need to keep an eye on inode count

probably doesn't matter much
I don't really like 'stable'/non-rolling releases, it's a pain to wait for fixes you need
you can check if you can install software and drivers you're relying on sanely
I've been using the same install of Arch for four years and stopped getting breakages after ~1 year, when drivers caught up to my hardware

background: i'm basically a retard
realisation: create ml by apple incorporated works?

should i try gathering a bunch of yeoni pics and a bunch of not yeoni pics and put them in create ml
yeoni-or-not-yeoni classifier
obsessed
I think Fedora > Ubuntu > Arch > Suse
don't like when too many updates so Arch is on 3rd
but Ubuntu's outdated base system might be inconvenient, Fedora looks better
but I haven't used Fedora much, not sure
also heard good things about Suse such as Tumbleweed, but it's much less popular so less howtos
yeah the first three are safe recommendations imo
I think a mix of different models is optimal
something like:
beta/unstable/git-master for things that give fast and important updates such as compilers, encoders
rolling for most other CLI/GUI tools such as browsers, editors, docker
stable for core system libraries which shouldn't break your workflow just when you clicked update
you would never want to install browser or yt-dlp from Ubuntu's package manager because you want them to be always updated to the latest
nowadays most GUI software in Windows/macOS can update itself to latest versions so it's not a big problem, but a bit harder with CLI tools which are just on github as source code
>With a Zimaboard plus PCI SATA plus low end 16T HDDs we can get 1PB for 64 disks * $250 + 13 boards * $240, or for $19120
https://www.theverge.com/2023/10/26/23934216/x-twitter-bank-elon-musk-2024>It’ll be on our platform. Money or securities or whatever. So, it’s not just like send $20 to my friend. I’m talking about, like, you won’t need a bank account.”
people have already gotten fuckd by apple card, imagine a tw*tter as your bank
this whole saga has to be some ultra elaborate gigatroll

i tried chromeos distro. native apps (non web app) might work fine but where is drag and drop?? i need it for mpv
anyone know how to get drag and drop?
Is there like a clamp or mic stand i could buy to also occationally use to keep a sauce bottle (or whatever) upside on top of a plate for a long time to empty it
>CLI tools
you can use choco, winget (windows)
or macports, brew (macos)

I can't read postgres explain execution plans
it's over

>Price for 8TB of TLC generic is currently 170 USD. QLC is cheaper than that
where samsung 8tb qlc is motherhecking 380 USD
ask chatgpt to explain

chatted with my chingu mr. copilot and he helped me increase work_mem at least the query works now though still bit slow at 2 seconds
>copilot
do you pay for the subscription? I thought about using it but don't want to pay for the basic stuff
also, help me choose icons collection: https://icones.js.org/
there're too many options
>Congratulations! You are eligible to use GitHub Copilot for free.
wait
so it works
but requires proxy because reasonsneed to test
also found other open source implementations like https://news.ycombinator.com/item?id=37940572

yea some code kinda repetitive to write without mr copilot
the chat part can be dumb sometimes since it cant read the file as context if the file is too long similar to chatgpt
idk abot icons heroicons seems simple
do you have
enableAutoCompletionsset totruein vscode?I found you can trigger it with
Alt+\manually, not sure if I want to see those auto completions all the time, it distracts memaybe need to get used to it
also afraid about sending all my code to server all the time. not like I'm not googling every line of code anyway
--proxy-pac-urlnot working in VS Codeso I have to proxy all traffic of VS Code via
http_proxyor maybe route
github.comvia VPN system-wide but I don't like it much

eligible for free but not able to use due to location? dang
looks like yes (i don't change defaults much)
it takes a bit of times before suggestions plus can always press esc so its fine
but yeah it sends everything maybe one day localpilot or something will have nice experice and i can use it instead
% du -sh node_modules/@tabler 166M node_modules/@tabler
>eligible for free but not able to use due to location
tough times
well, should work fine via proxy too
I'm using wireproxy now, comfy tool (
localhost[HTTP PROXY] → Wireguard → remote host)
I think ionic is optimal
feather is nice but not enough icons
tabler is too much and quality seems worse
oh no, in ionic it's jus 3 version of the same icon so just 400 icons each
will try tabler then. it's all so tiresome
there's also material icons by google
trying it, some suggestions seem to be nice
but can't do even simple stuff like "fix framework imports" when I ask it
maybe I'm doing it wrong

헐
is that cheng xiao?
what about https://github.com/jmorganca/ollama
https://github.com/David-Kunz/gen.nvim
https://www.youtube.com/watch?v=FIZt7MinpMY
https://github.com/hinterdupfinger/obsidian-ollama
the worst thing is that everyone now shills their own NN stuff but most of it has to be shit
but to see what's shit and what's not you have to try using it for few days/weeks at least
nobody has time to try all this new stuff

귀여운데

oops wrong thread
i havent used it much but its probably just a regular chatgpt 3 with currently open file as context
gotta just wait until cool people solve it and then make a one click vscode thingie
i dont have computer resources for LLM anyway
>귀여운데

it's the ml hyeseong what can you do
why stable diffusion is so shitty at generating logos? it took me just few tries to generate nice logo in DALLE3, but I spent all night yesterday with stable diffusion and that shit only generated complete garbage
people can't stop shilling their shit huh

I like Copilot nim now, it really makes me write code faster
not drastically, but maybe by 20% at least
just need to stop getting distracted by suggestions too early. i.e. I have to write something meaningful to make it autocomplete it. but it tries to autocomplete even when I wrote just single word and my stupid brain looks into that autocompletion and loses time and focus

im not sure if i notice the early suggestions anymore, maybe sometimes so shud be fine
>if i notice the early suggestions anymore
it's like when you type with someone else watching at your screen and commenting it out loud
new M1 MacBook Pro
rich girl
>fix framework imports
oh, I'm stupid, you can just press Ctrl+. to make vscode automatically fix imports
used copilot for few days
I'm a bit scared now, sometimes it's too good at predicting my mind
can you see the prompt chatgpt creates for you for dalle3?
what if you put that into stable diffusion
>the prompt chatgpt creates for you for dalle3
dunno how to see it
also, do they use chatgpt directly? has to be more complicated machinery
apparently they take your prompt and turn it into some detailed prompt that works better maybe that's most of the magic between dalle2/sd and dalle3
>When prompted with an idea, ChatGPT will automatically generate tailored, detailed prompts for DALL·E 3 that bring your idea to life
I tried to ask ChatGPT for prompts for SD but it didn't help
but prompts from the google for logos also gave me shitty results
maybe there's something wrong with the model I've used
I read about Tailwind and Figma and now not sure if I need it
learning new tools is so complicated
I hated tailwind at first glance but now I'm starting to like it
the magic of not having to name things
for me the main pros is because I can just simply copy paste styled HTML components from the internet
I'm suck at design
otherwise BEM seems like a much more solid solution, if not prototyping of course
HTML + CSS is solved with tailwind
HTML + JS is solved with JSX frameworks
how to solve JSX components issue
there're a lot of libraries of components like material-react but not sure, seems like you often want to customize? or use with non-react?

https://www.material-tailwind.com/figma
interesting
you can create WYSIWYG design previews in Figma using some UI kits
then quickly add those components from JSX library to your web app code
seems to be better than trial and error way of designing web app directly, without design app

but then you would design without content on figma
isn't that way more difficult
isn't it better to put all the lay out all the content without styling and then at some point style them once you know what kinda stuff goes where (idk i cant desing)

>isn't that way more difficult
dunno, depends on a website I guess
sometimes I have rough ideas of the web UI I want to implement, but it's kinda long process to do all the HTML/CSS/JS code
so when I implement stuff out of my head in web app, it might be shitty UI and UX and I will have to re-do a lot again
with Figma you can iterate on prototypes faster and get idea about final UI and partially UX, so you can just implement the final version
maybe I'm just too slow at prototyping in JSX code tho?
https://www.figma.com/community/file/876022745968684318/bootstrap-5-ui-kit
but how would you restyle those components
seems like tailwind components are more customizable
anyway you can prototype with any UI kit in Figma, need to just get the overall feeling of the final interface

everybody wants your money nowadays
figma: subscription for pro use
sketch: paid
tailwind components: paid
material components: paid
figma files: limited preview but everything else is paid

oh you know figma i guess that works too then
im to disabled myself and can only work with what mr. browser gives me
>oh you know figma
welp, I tried it for an hour yesterday night and got rough idea about how it works
>can only work with what mr. browser gives me
you mean unstyled HTML elements like
<input>?take a look here: https://github.com/troxler/awesome-css-frameworks#class-less

i think it's cool people are able to create a job for themselves like that wish i coud do it

I think the root cause is greedy monopolist corporations like Apple, Intel and Microsoft
they sell their software/devices with a huge margin because greed
but tons of people use their products (because monopoly) so to make for living they have to milk customers as hard as they can too
fucking stupid capitalism with a rat race

i guess because software interfaces are not exchangeable they can charge whatevermoney makes switching too difficult
idk how that relates to someone making a some ui pack tho, at least most of those appear to be one time purchases, in case you need one
if i were using react i would probably try mantine or material-ui and build my ui around it instead of trying to design my own they are free too i think

https://vercel.com/blog/announcing-v0-generative-uimaybe ai will save hooman from design pain
I've just learned Figma and Tailwind

>if i were using react i would probably try mantine or material-ui and build my ui around
I've started with a bit cooler framework, but now I think maybe it was wrong because a lot of libraries are made for react
but with those Tailwind templates it shouldn't be a problem because JSX is the same
though in some libs like https://www.material-tailwind.com/docs/react/button they provide convenient wrapper components
for those horrible Tailwind classes mess https://www.material-tailwind.com/docs/html/button#button
so I'm still thinking how to deal with it
maybe I should port those components https://github.com/creativetimofficial/material-tailwind/blob/main/packages/material-tailwind-react/src/components/Button/index.tsx
to my framework, they look simple. but that would be tedious
maybe should have just started with React. but it's not cool
it's interesting that it also uses Tailwind CSS framework, so I can copypaste that to my project too. need to try, looks pretty cool
there's waitlist tho
so tailwind looks like a bit improved inline styles. the benefit is that your HTML and CSS are connected together so you can't break them by renaming some class or changing markup a bit. also can just copypaste single block of test, instead of HTML + CSS separately. so in old days we had HTML, CSS, JS all separated, but nowadays it's JSX + Tailwind all in one file
but it still looks messy, like old WYSIWYG HTML generators
also I'm a bit scared about those AI solutions, it may soon replace devs

>for those horrible Tailwind classes mess
on the other hand you own the full code so can do changes very fast
without looking what are the defaults of that framework and how to change them the way you want
but it's if you want to change and know what's the final look should be. if you're ok with default themes then React component solution is cleaner, and also faster to prototype. uh oh
>there's waitlist tho
maybe Copilot/ChatGPT can generate them too?
now I'm starting to get the full idea of Tailwind too. it's easier for AI to operate in, because everything is combined in a single chunk of code, you don't need to context switch between template and styles and keep track of connections. your context can be very small when you generate this
very cool if you think about that. did creator of Tailwind have AI in mind?

Thank you for joining the waitlist for v0 by Vercel Labs.
Please stay tuned for an invitation to get started.
it's interesting that you chat with it and ask to change bit by bit initial generated code
it probably uses ChatGPT API underneath tho? just a tiny wrapper on top of OpenAI's API
<button class="inline-flex items-center justify-center text-sm font-medium ring-offset-background transition-colors focus-visible:outline-none focus-visible:ring-2 focus-visible:ring-ring focus-visible:ring-offset-2 disabled:pointer-events-none disabled:opacity-50 h-10 w-10 text-zinc-100 rounded-full hover:bg-gray-600 hover:text-zinc-100">can browsers render that mess efficiently tho?
probably yes, but still looks horrible

tailwind brings semantic HTML tags back
classes are basically unreadable so you have to use nice tags instead to navigate in that mess
I've seen enough
>remove bg-opacity-50
might as well use keyboard at that point dumbass example
in this case you'd make components out of label and input the styling gotta live somewhere
>the styling gotta live somewhere
yeah but those classes are horrible to navigate it, with normal CSS props it would have been easier
https://www.radix-ui.com/primitives/docs/components/accordion
https://chakra-ui.com/docs/components/accordion
https://ui.shadcn.com/docs/components/accordion
what to choose?
https://developer.mozilla.org/en-US/docs/Web/HTML/Element/details
push back the decision and focus on content
><details>
interesting
>focus on content
I'm just thinking it's much faster to iterate on UI with a library of components when you don't need to reinvent everything from scratch
probably should have just picked React
of course it's not very cool to use existing solution for design but most people don't really care how efficient or unique the site is
but if you make very simple half-assed implementations for dropdown/popover/etc with basic markup/styles people would probably notice it and will think it's ugly
although it's not really hard to make JS logic for dropdown, it's mostly the styles and UX which should look nice and it's too long to do from scratch
can just copy from Tailwind templates but why not copy the whole React component in that case
>can just copy from Tailwind templates
oh this looks nice https://flowbite.com/docs/components/alerts/
>why not copy the whole React component in that case
harder to modify if you don't like something I guess
just need to be able to create those components fast enough
>mantine
oh it also looks nice but depend on react and components aren't look easy to port
also should be harder to modify the style to your taste because you install components as a library and had to override the classes on top which isn't very convenient (not like most people would want to customize it much tho)
flowbite (or maybe another similar Tailwind collection, haven't checked them much) looks best so far - you own the full HTML with Tailwind classnames which you can change however you want
and they also have small simple vanilla JS implementation for components like dropdown/accordion which should be easy to port to any framework
https://github.com/themesberg/flowbite/blob/main/src/components/accordion/index.ts

>you own the full HTML with Tailwind classnames
seems like it's the best solution for custom sites nowadays
it gives you HTML template freedom of Bootstrap (with React components you usually can't change shit in template, it's all abstracted out in separate library in
node_moduleswhich is bad for UI stuff)and also it gives you easy way to modify look of those templates (in Bootstrap you just have high-level classes like
dropdown)but not as easy as going with React and installing some component library and just importing the pre-made stuff into your project of course
https://flowbite.com/docs/forms/toggle/
https://preline.co/docs/switch.html
https://www.hyperui.dev/components/application-ui/toggles
which is better?
why do they implement those complicated
https://flowbite.com/docs/plugins/datepicker/
https://preline.co/docs/datepicker.html
if you just can https://developer.mozilla.org/en-US/docs/Web/HTML/Element/input/date

built in date element can be a bit meh https://gist.github.com/RobertAKARobin/850a408e04d5414e67d308a2b5847378
of course all the javascript date pickers probably have issues too so again use the built in one until its not enough

why does mpv crash me computer once every 3 months black screen and static sound until i turn off teh computer
>every 3 months
cosmic particle?
did she look at her tits?
>The not-obvious path forward -- which our elderly users cannot find -- is to tap "December 2022", which pops open this rolodex-type thing:
dunno, it's probably me, but I instantly noticed it as a way to enter the date quicker (and no, not because I remember it)
just the pure logic: designers must have the case in mind when you need to go back by 20-30 years or more, so there must be button somewhere. and that caret is the only one visible
but elders probably can't think that way
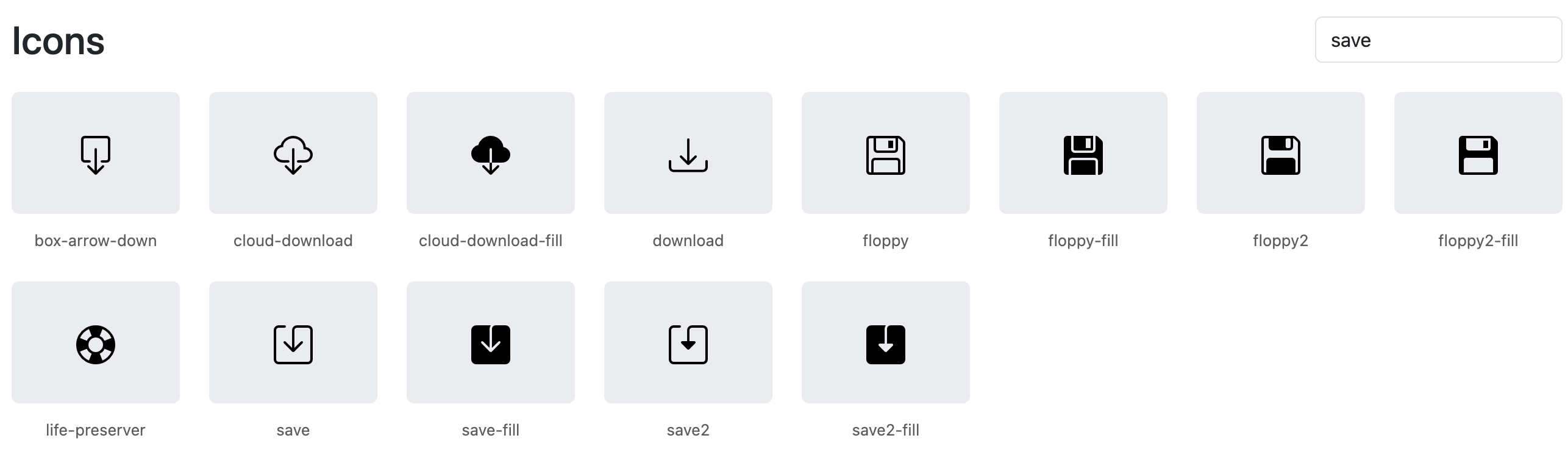
on the other hand, what would you use for the save icon nowadays?
zoomers don't know what floppy is, but other attempts to portray "save" are even worse
you can add "title" to the tag ("click to save") but it kinda sucks too
for me floppy is the best, but it's just me

am i the only one who has problem viewing 1080p youtube videos with mpv
if i try to mpv directly from youtubes usually i only get audio no video. if i download the video first it works, and 4k videos also always work
>if i try to mpv directly from youtubes usually i only get audio no video
might be because video chunks failed to download, check console for errors
I often have that with youtube videos too, especially when I do seeking to not yet buffered position
>check console for errors
oh right
[ffmpeg] Not detecting m3u8/hls with non standard extensionmaybe its a hls thing and I should just change config to always prefer vp9
mpv --ytdl-format=248+251yeah it works im dumb

why not youtube premium HD (AVC)
VP9 compression artifacts on 1080p are horrible tbh, it becomes bearable only at 2160p because bitrate is much higher. maybe on 1440p and 1080p60 too, haven't checked for a while
I can't understand how people not notice that VP9@1080p is garbage and google just let it be that way

same problem when trying with mpv directly it seems i just want a comfy setup
downloads at 1080p as mp4 for sure
omo Elkie
>i dont wanna wash me teeth its so boring
we have the solution for you: blizrush 7.0 - the revolutionary toothcleaning-sponge
>
wat

actually heck trying to optimize this thing
a materialized view will surely set me free
went from 2-15 second queries to 100ms queries and 2 minute refresh
what are you doing

working on my kpop archiver
my dumbass normalized schema is a bit slow to query so gotta resort to other options
>is a bit slow
how many data do you have
why are you talking about minute delays, it should be instant, you aren't google datacenter
https://nitter.net/multikev/status/1724908185361011108
https://github.com/tldraw/draw-a-ui>You are an expert web developer who specializes in tailwind css. A user will provide you with a low-fidelity wireframe of an application. You will return a single html file that uses HTML, tailwind css, and JavaScript to create a high fidelity website. Include any extra CSS and JavaScript in the html file. If you have any images, load them from Unsplash or use solid colored retangles. The user will provide you with notes in blue or red text, arrows, or drawings. The user may also include images of other websites as style references. Transfer the styles as best as you can, matching fonts / colors / layouts. They may also provide you with the html of a previous design that they want you to iterate from. Carry out any changes they request from you. In the wireframe, the previous design's html will appear as a white rectangle. Use creative license to make the application more fleshed out. Use JavaScript modules and unkpkg to import any necessary dependencies
bit different since they use api directly instead of chatgpt but i wonder if i wrote like this would i get better answers than just asking with a single sentence
https://github.com/SawyerHood/draw-a-ui/blob/main/app/api/toHtml/route.ts#L1 it's real
modern programming

risky but cool
btw, I found one issue with tailwind:
with CSS any changes of styles keep your app's state completely as it is, so you can prototype faster
but with tailwind, all your styles are inside JSX components, so if you want just to add 1px fix to the border or something, it will trigger app update
there's HMR, but it doesn't work good enough, state changes when you re-save your component's source file also I often have to Ctrl+R because HMR fucks up with the state and there're many errors in console (even though the app is completely fine when you refresh)
sounds true
components are probably best developed in storybook so you have hardcoded state for various situations
>storybook
oh, I looked at it, but seems overkill for simple apps where you don't have many components
I mean you will rather modify components for your specific view, instead of overgeneralizing them

i havent used react much yet but i did for a small browser extension and it was comfy its just a story file with some broilerplate and your state situations
would have been extremely uncomfy to test all the archiving states without it
>author info
>subscribed/not subscribed/ignored
>subscribing yes/no
>post info
>archived/unarchived
>archiving yes/no
>server response
etc
>would have been extremely uncomfy to test all the archiving states without it
hm, maybe
but I always retest app as a whole to be sure that the overall UX is perfect
maybe I'm spending too much time on it
what do you think about Open AI firing their CEO?

top of the news, curious to see if it actually matters one way or another
google also postponed gemini
openai seems to be focused on ai safety now
no AGI soon
oof webassembly is slow on iphone
wtf, I recompiled the program myself and now it 20 times faster
oh no, the name on npm is stolen

use a namespace so people think you are legit
meh, it makes
npm installandpackage.jsonuglyended up with smaller name than I planned. maybe it's for the better, looks cool
checked on iphone, my implementation is 2-3 times slower than on notebook there
but now it's fast enough
but I've also removed one feature to shrink the size, might need to add it
I don't understand the eyes emoji people use extensively to react on github issues and comments
wtf is that even supposed to mean

>mean various things like “you are seen,” “I am watching,” or “Intriguing!”
webassembly is faster than the native tool in my console
how is that even possible
maybe shell is too slow
also I put it in web worker because it was 150+ms
but now it's 10ms, should you even bother with such a short UI thread block time
>feel the AGI
lateral joins are so comfy for aggregating related stuff compared to the aggregate and group by every other column experience
but so slo
people talk about AI and AGI, but if you look at the state of projects at github, it's all developing fucking slow with tons of issues created years ago, nobody had time to fix them
I can't see computers replacing humans soon
or maybe it will be completely new code, not the already created mess that's managed by humans by hand, at the end of 2023
>The main thread is considered "blocked" any time there's a Long Task—a task that runs on the main thread for more than 50 milliseconds (ms)
>If the task is long enough (anything above 50 ms), it's likely that the user will notice the delay and perceive the page as sluggish or janky
barely found some heuristics
in my case it should be less than 50ms, so async worker isn't necessary
but dunno, what if slow old android?
>MineDojo: open framework that turns Minecraft into an AGI research playground. We collected 100,000s of YouTube videos, Wiki pages, and Reddit posts for training Minecraft agents.
fucking retarded HTTP2 which fucks all links from the same domain if there's packet drop
retarded idiots who shilled that google shit trying to convince everyone this is somehow superior protocols
why it's all so retarded
hm, it was HTTP3 which is UDP and should be fine
maybe Chrome is shit

its also extremely hecking difficult to handle in wireshark talk about troubling times trying to connect request to a response
though with http3 you cant see or do anything at all in sharkie so gotta disable it in browser feature flags
disable both http2 and http3 then
>wireshark
smartchingu

if only

>sharkie mentioned

>HTTP/2 is enabled by default and domains on Free plans cannot disable it.

>32.100ms
oh yes, I've found a way to make it 30+ ms with complicated query
so on a mobile it would perfectly be 50+ ms
so Worker wasn't useless
how do people use discord, it's a fucking mess
my brain hurts after just 5 minutes of using it, fucking information and visual noise everywhere
my google searches "how to disable X in discord" show that a lot of people having struggle with the noise
but devs probably keep all those annoying features so that normies don't miss something

https://support.discord.com/hc/en-us/community/posts/360048489252-Mute-all-channels-but-one
not possible to mute all server except one channel
https://github.com/plotly/plotly.js/blob/master/package.json#L72-L122
plsno
actually left join aggregate and group by every other column is still ass
gotta make the actual query a subquery, then left join and aggregate outside of that. took me from 13 seconds to 200ms
i'm le machecking stupid
the absolute state of npm
├─┬ d3@7.8.5 │ ├─┬ d3-array@3.2.4 │ │ └── internmap@2.0.3 │ ├── d3-axis@3.0.0 │ ├─┬ d3-brush@3.0.0 │ │ ├── d3-dispatch@3.0.1 deduped │ │ ├── d3-drag@3.0.0 deduped │ │ ├── d3-interpolate@3.0.1 deduped │ │ ├── d3-selection@3.0.0 deduped │ │ └── d3-transition@3.0.1 deduped │ ├─┬ d3-chord@3.0.1 │ │ └── d3-path@3.1.0 deduped │ ├── d3-color@3.1.0 │ ├─┬ d3-contour@4.0.2 │ │ └── d3-array@3.2.4 deduped │ ├─┬ d3-delaunay@6.0.4 │ │ └─┬ delaunator@5.0.0 │ │ └── robust-predicates@3.0.2 │ ├── d3-dispatch@3.0.1 │ ├─┬ d3-drag@3.0.0 │ │ ├── d3-dispatch@3.0.1 deduped │ │ └── d3-selection@3.0.0 deduped │ ├─┬ d3-dsv@3.0.1 │ │ ├── commander@7.2.0 │ │ ├─┬ iconv-lite@0.6.3 │ │ │ └── safer-buffer@2.1.2 │ │ └── rw@1.3.3 │ ├── d3-ease@3.0.1 │ ├─┬ d3-fetch@3.0.1 │ │ └── d3-dsv@3.0.1 deduped │ ├─┬ d3-force@3.0.0 │ │ ├── d3-dispatch@3.0.1 deduped │ │ ├── d3-quadtree@3.0.1 deduped │ │ └── d3-timer@3.0.1 deduped │ ├── d3-format@3.1.0 │ ├─┬ d3-geo@3.1.0 │ │ └── d3-array@3.2.4 deduped │ ├── d3-hierarchy@3.1.2 │ ├─┬ d3-interpolate@3.0.1 │ │ └── d3-color@3.1.0 deduped │ ├── d3-path@3.1.0 │ ├── d3-polygon@3.0.1 │ ├── d3-quadtree@3.0.1 │ ├── d3-random@3.0.1 │ ├─┬ d3-scale-chromatic@3.0.0 │ │ ├── d3-color@3.1.0 deduped │ │ └── d3-interpolate@3.0.1 deduped │ ├─┬ d3-scale@4.0.2 │ │ ├── d3-array@3.2.4 deduped │ │ ├── d3-format@3.1.0 deduped │ │ ├── d3-interpolate@3.0.1 deduped │ │ ├── d3-time-format@4.1.0 deduped │ │ └── d3-time@3.1.0 deduped │ ├── d3-selection@3.0.0 │ ├─┬ d3-shape@3.2.0 │ │ └── d3-path@3.1.0 deduped │ ├─┬ d3-time-format@4.1.0 │ │ └── d3-time@3.1.0 deduped │ ├─┬ d3-time@3.1.0 │ │ └── d3-array@3.2.4 deduped │ ├── d3-timer@3.0.1 │ ├─┬ d3-transition@3.0.1 │ │ ├── d3-color@3.1.0 deduped │ │ ├── d3-dispatch@3.0.1 deduped │ │ ├── d3-ease@3.0.1 deduped │ │ ├── d3-interpolate@3.0.1 deduped │ │ ├── d3-selection@3.0.0 deduped │ │ └── d3-timer@3.0.1 deduped │ └─┬ d3-zoom@3.0.0 │ ├── d3-dispatch@3.0.1 deduped │ ├── d3-drag@3.0.0 deduped │ ├── d3-interpolate@3.0.1 deduped │ ├── d3-selection@3.0.0 deduped │ └── d3-transition@3.0.1 deduped

>Trying to simulate three spatial dimensions on a flat screen will always be imperfect and make it difficult to read the data. However, it is very easy to graph three different data dimensions in D3. You use the horizontal and vertical layouts for two of your data variables, and then size, shape, color or shading for your third variable.
>If all three of your data variables are best represented by continuous numbers, then your best approach is to use a bubble-scatterplot, where your three display dimensions are horizontal positions, vertical position, and bubble size.
isn't it lame to omit third dimension just because "it's hard to display"
I'm actually thinking about 4D graphs, probably people already tried to display that too
https://www.desmos.com/calculator/ivk5qvhozf
https://www.desmos.com/calculator/kmmqs0eexd
>4D slider
oh, this makes sense


혼자 하지마!

why is she so fat?
baby?
I like something more energetic like
https://www.youtube.com/watch?v=S5LvhKbsHWU

not very realistic
when something doesn't work, I don't hold my head with hands (implying it's my issue), I swear like crazy to the screen, implying another stupid engineer made that happen to me
https://www.youtube.com/watch?v=SEwTjZvy8vw
they talk about advanced compiler stuff too fast, have to pause all the time
made query which runs for 600ms
and I was thinking it's too fast
queries suddenly become scary when theres a million row dataset
I just made it too stupid
run complex regexp on every entry instead of running it once for all items (realized it later)
even simple context menus you have to build from absoluut scratch on the web i guess there was a reason peope use those component libraries from the start
try https://flowbite.com/docs/components/speed-dial/#dropdown-menu
don't need library, just copy-paste few lines of HTML

kpop isn't getting younger it seems
so uh if you have a component with bg-blue-500 and then use the component and add some class like bg-red-500 so it becomes
class="bg-blue-500 bg-red-500"theres no logic to which rule is usedso you cant override things
it's over
yeah, you have to use something like
<div classList={{ "bg-red-500": p.error, "bg-blue-500": !p.error }}>
but you cant
<my-thingie class="bg-red-500">
yeah, I'm just thinking about that problem
the inheritance is very hard and brittle, because you can change some small thing in child component and break parent component which depended on something
better is to copy-past the full component and change it where you use it
or only accept props which can't break thing later
copy-paste isn't ideal but safer
well, they discovered it in Java decades ago, basic design patterns like https://en.wikipedia.org/wiki/Composition_over_inheritance
>small thing in child component and break parent component
err, I meant change base component and break child component
css always prefers the latter rule so I thought classes would be the same
but no now I don't feel so good
no quick fixing components in certain context, gotta bake some gigalogic into the component itself to take care of those situations
>so I thought classes would be the same
they are. you just have no control in which order tailwind put whose bg-red and bg-blue classes in the CSS it emitted
or maybe you can, just look at how it does it but anyway, not a good idea to depend on it
>bake some gigalogic into the component
yeah, oh copy-paste & change your private copy without the risk of breaking anything
the downside is that those implementations may drift and you won't have consistent look across web app
but I dunno how to do it better anyway, just unsolvable problem of software development in general
>they are
I mean classes in the CSS, not classes in HTML tag

https://www.youtube.com/watch?v=NrQkdDVupQE
I lost it on the black woman part
anyway, after using it for a while, it doesn't see too good. just a bit faster autocomplete
chatting helps only for simplest tasks and autocompletion mostly works for simple repetitive tasks
maybe I'm using it wrong, but often it's faster for me to type what I wanted myself, when wait few hundred ms while it autocompletes what it thinks would fit. because it might autocomplete not the thing I wanted and I actually lost 300ms waiting (I know I can type instead of waiting, but something inside me wants to let it think instead of abusing it with keystrokes or maybe because if you type too much it might not autocomplete at all. need more practice)
also doesn't help much with tinkering with existing code because if you edit inside string it seems to ignore that. only if you adding something at the end of the line
tldr; product is delivering 20% of what marketing promised, as usual
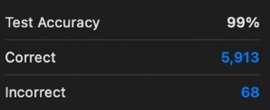
hopefully i'm still measuring the right thing but
omo
what model are you using?
are you tagging kpop photos?
is it a graph making thing then is cool
not only
you will see soon
what is a selca if you really think about it
selfie?
self-camera maybe
are photos by manager included
>A selfie is a self-portrait photograph
>A self-portrait is a portrait of an artist made by themselves
=> no
I wrote horrible messy code
does it work?
either
1. I have to put too much component-specific logic into the unrelated component
2. Or my component won't properly react to the state changes made by other components
my abstractions suck
dunno how to separate components and still make them behave nicely together
just wanting to do it beautiful
ok, I think I cracked it my mutating the state in other component instead of immutable shallow replace
hackish but works
I think that's a bit better than putting unrelated logic
things are a bit complicated when you deal with declarative reactivity
have to always remember to make everything declarative otherwise things might go out of sync
on the other hand, imperative UI is a fucking unmanageable mess which is much worse
maybe you can combine by using mostly reactivity but sometimes imperative approach?

some people online seem to swear by a single application or api as the only interface to the database.
makes me curious how I might make that work. currently all pieces of archiver (twatter, tistory, youtube etc) are their own programs that directly access the database
if i had a single database api all the archivers would have to work via post requests to the database owning app, but if i did manage all that i could then try using sqlite instead of postgres. that might be fun
hopefully rubber duck has some ideas about this while i try to remember how my code works, might be the dumbest refactor ever
>currently all pieces of archiver (twatter, tistory, youtube etc) are their own programs that directly access the database
so you have copy of database wrapper objects/queries in every app? sounds not very effective
you may make small private library which all those apps use which abstracts the DB access
or just merge all those sub-apps into a single project, optionally accessed by different CLI utils. or maybe just a single one like
./app subapp1 --args,./app subapp2 --argsabstracting DB access with HTTP API may work, but dunno, sounds more complicated than shared DB code
>i could then try using sqlite instead of postgres
sqlite is only for small databases
you had problem with query performance, you probably have more data than what's suitable for sqlite
may try nosql like mongodb if you don't care about normalization/transactions much
which may be true for simple archiving apps which just store metadata
people tend to hate mongo but SQL feels meh every time I use it, so much useless dancing around the data
and the DB daemon itself is too complex, requires monitoring, tuning, etc
but seems inevitable for reliable data storage, mongo and other nosql trash isn't there
lowendtalk is one of the shittiest forums I've seen ever
worse than facebook
yet many people share valuable info there
https://news.ycombinator.com/item?id=31886907
pain
>This is a consequence of how DisplayPort is designed, so most DisplayPort monitors will behave this way. If you don't want this behavior, don't use DisplayPort.
>DVI and HDMI provide a small 5 V power line from the source to the display. This provides a minimal amount of power to the display so that its identification data can be read. Since this power is provided by the source device, it does not depend on the power or state of the display. Even if the display is completely unplugged from the wall, the source will be able to read it and see that a display is attached.
but HDMI doesn't work well in macOS either
https://www.youtube.com/watch?v=Z1EqH3fd0V4
but there is a fix
not sure I want to thinker with configs that much
I bought mouse with bluetooth connection because I didn't like the dongle
but then I also bought monitor with usb-c and hub so I can connect mouse's dongle there and have just one cable
what do
maybe return the mouse? but I hate returns

also bought that thing
spending too much money on electronics this month

macos is dumbo
just to use it remotely on a 4k monitor you need to attach it into another 4k monitor or download some rando's binary from github that creates a virtual display that has a proper resolution
mouse usb dongles are so comfy, i was looking at usb dongled headphones earlier to avoid bluetooth memes but they all seem to include a charger so they are too big. i'll have to keep using the bluetooth headphones and bare the magical times every week or so when they stop working for absolutely no reason for half an hour
i've even moved in the middle so it can't be some electromagnetic mystery device my neighbor uses at random times

>to avoid bluetooth memes
well dongles also use 2.4 GHz, just with a proprietary protocol instead of bluetooth. but maybe that gives them a bit of freedom to implement the connection better. or maybe worse, how can we be sure they tested it in all possible scenarios like when you have many 2.4 GHz wifi AP around
I remember reading reports where people were having issues with multiple Logitech dongles conflicting with each other or something like that...
also I'm not sure the dongle will work OK if I connect it to the pic. I mean what if it's metal parts inside the monitor so the signal won't go through (I had that issue with bluetooth adapter connected to the back of my PC before)
well, can just test, the only problem is that I will receive bluetooth mouse sooner than the monitor so less time to return the mouse if the dongle + monitor solution works also the mouse is nice, can't choose between being cheep and playing with a new toy. welp

i have that monitor except with ergo stand logitech maus dongle at the back of this thin monitor works extremely normally even if i go 10 meters away (microwaves go baunsi bauns https://www.youtube.com/watch?v=QqggrSpICM0)
i mostly like dongles since you can switch the computer with the click of a kvm, but avoiding all the bluetooth issues makes them amazing. devices with wireless receiver have existed for a long time, maybe they are just more polished
>i have that monitor except with ergo stand
which model?
>microwaves go baunsi bauns
dunno, my old bluetooth adapter definitely couldn't go through the metal PC case. maybe because of very low powered transmitter tho, logi dongle could be better (because wave loses energy when it's reflecting, compared to when you have the transmitter in a line of sight).
but I believe you, logi adapter will probably work well. welp, should I return the mouse then
>but avoiding all the bluetooth issues makes them amazing
dunno, bluetooth works mostly fine for me. at least much better than occupying port of the notebook with a dongle. people use usb docks but I don't trust those things to carry signal to my monitor, it doesn't work well even if I connect it directly... or maybe if it's a very expensive thunderbolt hub then should be fine...

>thunderbolt
>thunder thighs
correlation?

lg ergo 32"
i use a regular ol' usb 2.0 switcharooni as my kvm for mouse mic and keyboard, these bad boys don't need some mega bandwidth thingymagic
just tested the dongled directly in the back since you wanted to kno
LG 32UN880-B?
I thought about buying it too
but 32" with same 4K has less PPI also I have another 27" so decided should be ok with 2x27
also I didn't read any reviews or anything. just saw the BF deal, checked that it's relatively ok and just bought. compulsive purchase
>these bad boys don't need some mega bandwidth thingymagic
I mean when you carry several display signals (4K@60 requires 12.5Gbps), the power and also few USB2.0/3.0 devices such as dongles/external disks through the single cable
if you connect display and dongle separately then you don't need dock
>as my kvm for mouse mic and keyboard
why do you need that? Linux + Windows?

oh no, I checked, I would have to pay for delivery cost for returning the mouse
which will cost me 30% of the price of the mouse
what do, it would be easier just to keep it
oh, I found another way
I can just don't receive it and it should be sent back without additional cost
I think I will try it

i need scaling even on 32" blind nim at your service
maybe if you have use for it, i just use desktop so no need for dongle less devices
>so no need for dongle less devices
I have a need for free ports because it sucks to disconnect everything every time I want to work in different place
so monitor's dock should help me with that, don't need bluetooth mouse. and I quite like my current mouse anyway (g305)
but having the new cool mouse would be great too, you don't need to replace batteries there because it has battery. and it also has horizontal scroll wheel which is useful sometimes. not sure yet

grug no understand thunderbolt

yeah i share code currently
sqlite would be fine for me at millions of rows scale
the performance problems were due to me dumb ass aggregating related data for each row while seeking instead of after it
>nosql
i'm not that crazy sql database integrity checks save me from a lot of trouble
some datalog database might be interesting tho if it existed but not that massive java daemon called datomic>requires monitoring, tuning, etc
another reason sqlite would be nice but the rewrite would be massive so i'll just continue dreaming for now
what about 꿀벅지
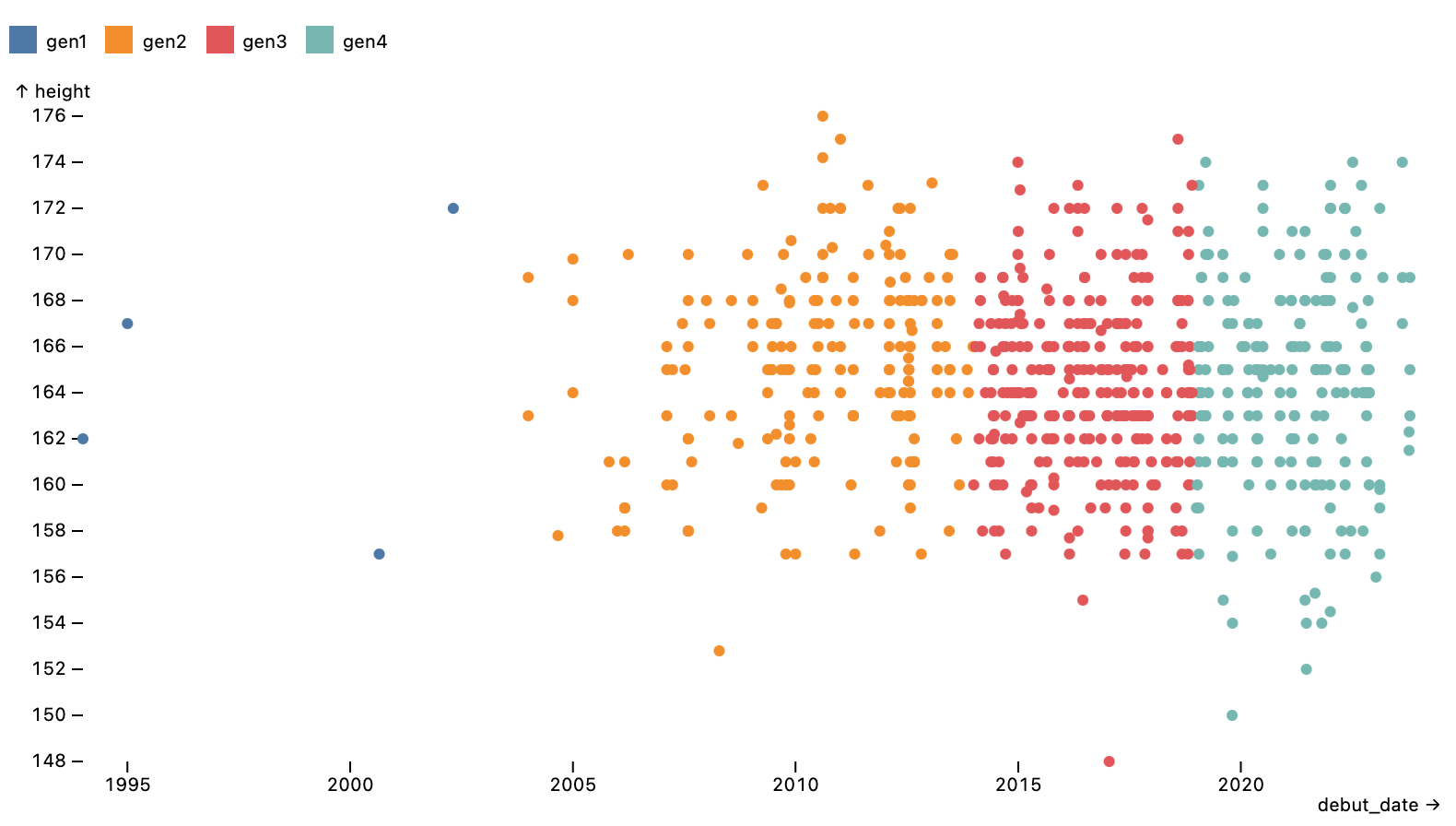
but they are becoming smaller

here is more visible
but probably just lack of data

not because of height/age correlation btw

spent few hours setting this up
I planned to put secondary monitor on the right, but power cable isn't long enough because plug is on the left. have to put it on the left
also seems like main horizontal + secondary vertical would be better layout, because 2x27" horizontal require too much neck work
but if secondary is vertical then power cord may be enough to put it on the right. or many use cord extension. dunno
anyway seems like no much difference if secondary on the right vs on the left
also the new moni setup doesn't play well with my deck lamp had to unmount it. I use it rarely but sometimes it's useful


seems like people put secondary on the left
maybe because main = strong hand = right
secondary = left
people use notebooks in clamshell mode, have to buy stand, keyboard, can't use internal panel, can't use speakers, can't use fingerprint button, have to setup brightness/volume buttons with new keyboard
why would you do that only to avoid neck pain? maybe it's better to train neck muscles
https://www.youtube.com/watch?v=Dvt7ZPL15xU
Ning looks great in vertical orientation
but vertical monitor seems not very useful
once you open some page which is supposed to be watched in landscape mode, the UX become shitty
even if you have main monitor in landscape, seems like it's better to have secondary in landscape too
should I buy mx keys mini + laptop stand tho?

I couldn't get used to double monitors so i just go with the one at least i can pivot for the ningies when necessary
maybe if there was a fun litl monitor that was as tall pivoted as my main monitor landscaped with the same ppi and i managed to avoid the cable hassle somehow

just simply buy an apple external keyboard with apple t2 security chip and touch id
>I couldn't get used to double monitors so i just go with the one
I just wanted 4K monitor because macOS doesn't play well with 1440p monitors (because it can't into sub-pixel rendering). and since I already have one, then it would be 2
also I currently use internal screen + external monitor and it's not always enough to put all windows I want (when developing you often need many windows open). so 3 (2 external + 1 internal) seems like the absolute minimum
>i can pivot for the ningies when necessary
dunno, feels like a chore to rotate it back and forth even if you have a nice stand. better to have separate portrait monitor if you need it often. but seems like in reality vertical monitors aren't very useful
>with the same ppi
does it matter? at least macOS doesn't care if different monitors have different PPI
>i managed to avoid the cable hassle somehow
that thingie >>997402 has a nice niche for cable management
too expensive
also, I don't understand why do they use clamshell mode with separate keyboard if you can type on notebook's keyboard and look into external monitor. weird
>too expensive
hm, just checked, actually just few dollars more than mx mini
logitech nim is too greedy
but there's also MX Keys Mini Combo with mx anywhere mouse
uh huh, shouldn't have looked into the keyboard/mouse stuff
I was fine with my current mouse, now I want all the new shiny stuff

yeah! apple peripherals are actually very cheap you wouldn't want apple peripherals division to lose revenue would you
weird video, why do they compare thunderbolt 4 (which can deliver 40Gbps) with some random USB-C which is probably just 10Gbps
but definitely you can find cheaper than Apple's on aliexpress. but it wouldn't be very cheap either
also I just said that logitech accessories are pretty expensive (at least the hyped one like mx mini/mx master series). I didn't say that apple's accessories are cheap
also there's error in the video. when they talk about amazon's cable they say there's no IC inside and that it's fine to charge stuff
but to charge over USB-C you have to have controller
stupid video

>hyped
keyboard hype huh
https://youtu.be/HzDN8vT2u1M?t=485
this would solve half my problems with blutooth at least
>the webm
>this would solve half my problems with blutooth
what? the dongle?

change device with a button
oops it was https://youtu.be/HzDN8vT2u1M?t=387
it was copy current time like the text says not copy time to where cursor is located
oh yeah, some bluetooth devices support multiple paired devices
omo Juri!
also you didn't answer why do you need multiple devices

hey!
anyone know how to use the new yt-dlp format sortters and stuff?
270 mp4 1920x1080 30 │ ~1013MiB 5300k m3u8 │ avc1.640028 5300k video only 137 mp4 1920x1080 30 │ 644MiB 3450k https │ avc1.640028 3450k video only 1080p, mp4_dash 614 mp4 1920x1080 30 │ ~ 555MiB 2905k m3u8 │ vp09.00.40.08 2905k video only 248 webm 1920x1080 30 │ 291MiB 1561k https │ vp09.00.40.08 1561k video only 1080p, webm_dashi live in the youtube-dl age and still have
bestvideo[ext=mp4]+bestaudio[ext=m4a]but its bad now and downloads 614 (vp9 mp4?) which is not super bad but I want 137 or 270
-S vbrmaybe
thanks

섹시 쥬리 올려 주세요
why do people buy those stupid mouse pads
I can understand if for cyber sports or if deck's surface is shitty, but 90% of people shouldn't need that
yet if you watch youtube videos, most people have them
is this cargo-cult/marketing trap? must be a really big one
found on the internet
>scratches the deck
>wears bottom of the mouse
dunno, I can't see those issues. but I don't game
>to avoid bluetooth memes
>The thing is, Bluetooth has a TONS of parameters in the link layer to keep the connection goes smoothly and Apple has published a Bluetooth guideline document for peripheral venders, telling them how to set these parameters within a given range that best fits for macOS. If venders disobey, it will end up like what you get.

just gotta hope the device maker, the chip manufacturer and the operating system have all the specs and additional protocols implemented with a single vision
anyway its nice that it works as well it does, while making me curious why sometimes it doesn't work
>Honestly the MX Master has ALWAYS felt like dragging a bag of sand or using a fucking twitchy laser pointer on the side of a barn 300 yards away, with no in between. I ended up going with the G305 which has a much higher DPI and feels amazing and very precise when I need it to
a lot of people are complaining about that productivity mouse and say that simple gaming mouses from Logi are better

>scratches the deck
>wears bottom of the mouse
sounds like a bait
anyway i suppose if someone is used to a certain feel when moving a mouse, or assume it helps with their gaming performance mouse pads are just 15 buckerinos so they might as well buy one to make sure they are not missing out
or maybe they just havent tried moving a mouse without that mouse pad
looks kinda dumb and heavy, are you supposed to rest your entire hand on it or something
>or maybe they just havent tried moving a mouse without that mouse pad
probably. or shitty decks. I'm using nice smooth white decks from IKEA and I have zero problem with moving mouse on that surface. neither notice scratches. wearing mouse's plastic pads on the bottom could be an issue, but you probably can notice only if gaming every day for few hours
>are just 15 buckerinos
I can't stand when half of my hand on different surface than the rest. and when I have to constantly move mouse to the center of the pad. and constantly move the pad to the center of the deck. must be my OCD thing tho
huge pads which cover the full table should be better, but I don't like that there would be dirt underneath. or if you spoiled some water. also they're expensive
>are you supposed to rest your entire hand on it
yeah, palm grip
>looks kinda dumb and heavy
it's basically in every "productivity deck setup" video on youtube, and 99% people with mac use it. even Juri here >>998053 ➡
I took the bait and bought it too, now regretting

i think that was just some staff's computer
for me it's yuri's true love logitech g®️ series g305 mouse
also its plastic and has rubber feet so no need to worry about stratching your deskalthough since you are using a mac it may actually require mx master: that mouse has that weird fast infinityscrollwheel. a normal mousewheel step is 0.1 lines scrolled on macos (=dogshit), and while you may try another randomguy's random binary from github to try and emulate a normal size scroll step (4 lines or something) it will not work well and will also fail in many places

>just some staff's computer
yeah. most idols can't afford computer, only phones on a second year if they're lucky
>yuri's true love logitech g®️ series g305 mouse
lol. it's g705 tho (for the girls). g305 (for boys) is a bit different
>and while you may try another randomguy's random binary from github
yeah, I'm using UnnaturalScrollWheels to revert the scroll direction (because macOS is fucking stupid)
and it also has option to scroll multiple number of lines per wheel. works mostly fine, rarely it scrolls too much like in devtools (because it's a small window at the bottom of the page and you want slow scroll there)
a long time ago microsoft also had mice with those funny infinitywheels, back then they were called stepless scroll wheels or something
if you played cs with it it was really hard to pick a weapon since it scrolled through weapons really hecking fast
I bought Microsoft's Bluetooth Mouse 3600 once and all it gave me were carpal syndrome and broken scroll wheel in half a year
worst mouse ever, even Logi's Pebble is much better
technology

I also bought a non-logitech mouse once (razer) and it broke in a year
can only trust logitech
https://www.rtings.com/mouse/tests/control/latencyhaven't seen this site before
>Coates was moving when the photo was taken, so when the shutter was pressed, many differing images were captured in that instant
well, you can disable that feature
>can only trust logitech
not even them. I had some cheap white mouse of them and the rubber on the sides fallen apart in a year
also I still have K360 wireless keyboard and the latency is fucking horrible. if you type fast enough you can easily notice the lag. basically unusable
but overall many their products are ok, especially if you check reviews
they post opinionated recommendations for high mid-range products. pretty safe to look into
but sometimes they recommend too few options to choose from. e.g. here https://www.rtings.com/monitor/reviews/best/monitors-macbook-pro they only have Dell U2723QE and Dell S2722QC and don't mention any non-wide LG at all
no mentions of g305 here https://www.rtings.com/mouse/reviews/best/macbook-pro either
kyaaa waifu with a hourglass body
looks like each of those recommended mice has stepless scrolling. g series doesnt thats why
btw windows and recent kde are the only os where a basic scroll wheel works apple, chromeos and i guess wayland went craxy for cocopops over touchpads for some reason
in pebble scrolling isn't stepless
probably only added since it's modeled after apple mous
at least they mention its garbage
>they mention its garbage
I was actually using it for an year (I'm not that https://www.youtube.com/watch?v=1taLXjVxB4U)
but yeah, the experience isn't great
>an apple external keyboard with apple t2 security chip and touch id
suddenly I've found this https://www.youtube.com/watch?v=hz9Ek6fxX48
so you can buy $150 keyboard, extract touch id sensor, made button of it
then buy keyboard you actually like
>MBr/s 10
>vda busy 100%
the absolute state of cheap VPS
>checked prices after the "black friday"
>it's all the same, maybe $5 more max, sometimes even less
I fucking hate those jews
they shill you into waiting the full year when you need to buy something, but the actual sale is pure fake, no real deals at all
but then they suddenly do a huge discount on a some thing you've recently bought for the full price
shilled myself into screenbar lamp
now trying hard to avoid buying keyboard + mouse + laptop stand (and maybe even mousepad) because all "productive workspace" youtube videos have it
I don't really need it, but buying new geek toys is so nice. also I think it's not healthy for the neck to stare in the notebook's screen as I usually do. but always do "healthy things" is too complicated anyway

>screenbar lamp
bro
what possible purpose
>keyboard + mouse + laptop stand
what is this a table?
>not healthy for the neck to stare in the notebook's screen
this is probably true, just look at the pretty lg display

>what is this a table?
didn't understand
I mean if you want to look at notebook's screen without lowering your neck too much, you either need to put it on notebook's stand (like pic) or put it in clamshell mode. either way you need external keyboard
>just look at the pretty lg display
technically you can use notebook as a keyboard, only looking at external screen. but it's a bit stupid to not use its superior display too? (for which you need a stand)

sounds painful, in that case def get it and look at the stars instead
too bad can't look at Jeewon's ㅉㅉ
oh no
I thought maybe mx master not so good and mx anywhere is better, but people don't like anywhere either. is g305 just best mouse?
i usually just into a shop and try how they fit my hand
everything else is secondary
>G502 X
oh yeah, I think I should do that
the closest shop is about 40mins from me tho so was lazy
but overall too many people complain about mx master's polling rate and I hate when thinks aren't fast enough, so it's probably bad choice anyway
125Hz is pretty bad when you are used to 1000 yeah

ok, I've bought the keyboard and stand
I will check the mouse in the shop tomorrow, maybe it's not that bad
but probably better to return to save some money because the current one still ok



이야
wrong channel
even after I've bought all this, my deck still won't be as cool as those youtubers have
could buy in next year
some ideas:
- headphones (I have few, but I don't want to deal with charging so just use notebook's speakers or airpods sometimes). maybe make charging dock or buy one which has it?
- thunderbolt dock. will allow to run everything through a single cable, also also connect accessories comfortably
- better cable management but dunno if it's worth to make everything more complex
https://www.youtube.com/watch?v=_u8LCgL7hcg
cool thing

most stories ive read only is about people getting bored of using it since you have to move your hands away from the keyboard and look
pretty curious if you can make it work though so go for it and report back
oh no, I won't buy it. I don't like extra shit on my table
just the idea of having more custom physical buttons looks cool
the same as touch screen vs buttons in cars
>getting bored of using it
the absolute state of society
first they make 100s of videos on youtube "look at this new cool thing I bought, how convenient it is, my productivity became 100x better after I started using it"
then after a year or so they make another 100s of videos "the sad truth about X: it's actually not so convenient, so I stopped using it. here's why"
basically unstoppable hype train of praising and then condemning any new thing
yours?
>toddler english
idk why you're not allowed to reply to other chatters on these streams
you’re supposed to simp to the streamer herself
잇엇슴다 = 있었습니다?
checked the mx master 3s in few shops
unfortunately it’s packed so couldn’t turn it on and check the cursor movement, just shape
welp

oh I usually just open the box
unless it's one of these cursed things you have to completely destroy to open
>check the cursor movement
can you switch your current mouse to 125Hz?
I mean they opened the box and I checked how it feels in the hand. but the power on button is under the sticker and so I couldn't check how it actually works with PC
>can you switch your current mouse to 125Hz?
well, I received the mouse today. decided I will sell it on local ebay for a little discount if I won't like it
the FOMO is too strong
ok nice

tried
ok, I don't like it
the polling is fine, but scrolling is weird and it's too heavy
but anyway, I had to try it myself just to be sure. those youtube shills are retarded, as usual. I can't believe they all use that shit (unless they're all paid by logi)
I think I need to buy something like g502 if my g305 breaks
I couldn't believe g305 is so cheap and so good at the same time

maybe you get used to it
my hand hurt a lot for an entire day going from mx518 to g305 and since then it's been lovely
its something IVE been thinking about lately, there are people out there who watch the 0.5 second macos virtual desktop switching animation a hundred times a day. maybe its not that bad once you get over the initial pain?
>maybe you get used to it
maybe, but I will try to sell/return, I don't think it's worth the cost for me
>mx518 to g305
you have g305 too? based
>its something IVE been thinking about lately
lol, I read it as girls at IVE were thinking about macos virtual desktops
very nice/omo Wonyo!
>0.5 second macos virtual desktop switching animation a hundred times a day. maybe its not that bad once you get over the initial pain?
yeah, it sucks. but I don't use virtual desktops much. and with many monitor setup you don't need to do it much too
but there's yabai which can fix it https://github.com/koekeishiya/yabai
I didn't try it because I don't want to modify the default behavior too much (because it might lead to a lot of problems in the future)
>0.5s
>hundred times
just 50 seconds a day if you think about it. basically nothing
https://www.reddit.com/r/youtube/comments/igytta/how_can_i_stop_being_recommended_reaction_videos/
please stop it
I want to kill humanity just because of having it in my recommendations
mechanical keyboard is such a horrible case of consumerism
people discuss switches, layouts, shapes for months, overpaying for all that stuff instead of just doing something productive on the computer
I mean ok, it's a hobby for some, but it seems you just spend too much money for little value and greedy companies are always happy to sell you that overprived shit which you want to buy because it's the current hyped thing on youtube
and it's much worse than the overpriced brands like logi
with logi you buy expensive thing but you do it once and happy with it
with custom things you always feel the need to buy more and more because of how human brain works. "are those new shiny switches better? need to try"
i just searched for a mechanical keyboard with slim keys (so i don't have to bend my wrists or use a wrist rest) and a nice ansi layout (no numpad, normal arrow keys, no fn key nonsense and especially no ISO) and bought it
if i wished anything more it would be a washable keyboard since taking off all the keys to clean under them is a lot of work but idk if that exists
>slim keys
>no numpad, normal arrow keys, no fn key nonsense and especially no ISO
oh, I like that, though you can try something like "mx keys mini" which is almost like that
but I meant those people who will buy different switches every month because some new company shilled something on youtube
if you just found a product you needed and bought it once, it seems fine
don't you need Fn keys for VS Code tho?

>especially no ISO

i mean the key called Fn
tho actually now that i look at my keyboard i do have one but it's on the right side (used to control some backlight settings it appears). i never use right side meta keys for anything so i had fo'gotten

oh, so yours is like 75%
I like the compactness of 65%, but F keys are useful in VS Code
and also to quickly control brightness/volume
80%
i'm too lazy for two handed page up/down
I don't have home/end/pg up/pg down on my notebook's keyboard and it's a pain
especially because different apps have different hotkeys, sometimes it's Fn+Arrow, sometimes Ctrl, sometimes Ctrl+Shift, I can't get used to it
there's even a 60% keyboard for the cool guys who use vim motions everywhere
there's 40% too and split like https://www.youtube.com/watch?v=YlZPnh9cbQU
it looks cool, but I bet it's not really useful in real life
and even if you're stubborn enough to force yourself into using it anyway, I bet those people secretly hate it too

what to do with right side meta keys seems liek a waste
macos has this nice thing
https://lowtechguys.com/rcmd/but macos is also stupid so i'll never be able to use it
oh interesting
isn't it better to use multi-monitor/multi-desktop solution tho because it's hard to keep context of the app in mind
>macos is also stupid
very. also expensive and closed
but I like to have reminders I typed on computer to work on a phone in a nice native app
https://www.youtube.com/watch?v=5RN_4PQ0j1A
16-key keyboard

received monitor lamp like pic
pretty good and doesn't take space on the desk
but the light isn't that bright of course, it's only 5W
at least you'll see the dust on your monitor and remember to wipe it more often no but what is it for im curious

I watch the gnome ones now, pretty and not too slow
reminds me I've been meaning to swap my keyboard's mini USB socket for a type C one
used it for seven years now btw, TADA68

>you'll see the dust on your monitor
oh yeah
>remember to wipe it more often
I don't care https://www.youtube.com/watch?v=4MgAxMO1KD0
>but what is it for im curious
like a lamp but you mount it on a display instead
>TADA68
65% master race
don't need F keys?
>don't need F keys?
not much, I just press Fn and the number when I do

https://blog.twitch.tv/en/2023/12/05/an-update-on-twitch-in-korea/
youtoby might be next
what will happen with my favorite KBJ???
>our network fees in Korea are still 10 times more expensive than in most other countries
I don't understand
ok, they don't want to host servers in SK. host it in Japan or Taiwan or whatever. just few ms difference
can't believe this bullshit. must be government's request
shes crying right now on stream
https://www.twitch.tv/golaniyule0https://www.koreaherald.com/view.php?ud=20220421000740
i guess as long as they have business there it might get costly 4k fancams might be of the past very soon
>The planned revision to the Telecommunications Business Act -- also known as the ‘network usage fee’ bills -- would require global content providers to sign mandatory contracts with local Internet service providers such as KT and SK Broadband to standardize obligations to pay fees for using their networks
so they force you to pay for incoming traffic? weird
>고라니율's content is intended for certain audiences
>It may contain: Drugs, Intoxication, or Excessive Tobacco Use, Sexual Themes
>This content may not be appropriate for you to watch.
>so they force you to pay for incoming traffic?
as far as I know, in most other countries big sites connect to the country's nearest IX and all tier2 ISPs inside the country also connected to it so the traffic sharing is free
looks like netflix paid up https://about.netflix.com/en/news/sk-telecom-sk-broadband-and-netflix-establish-strategic-partnership-to
what about youtoby
isn't netflix flopping?
>what about youtoby
https://news.ycombinator.com/item?id=38539167
>I watch competitive StarCraft 2 and Brood War, both of which only provide the highest quality stream through AfreecaTV. This isn't something I've looked much into, but I swear that AfreecaTV also has a way better bitrate and encoding than what you get with unpaid YouTube.
will watch fancams from afreeca unless they make outgoing traffic paid for 외퀴
>For video, they generally reduce the video quality throughput, eventually reducing bitrate, causing buffering, and generally making your experience miserable unless Twitch, Youtube, etc pay the providers NOT to on behalf of their users. Cellcos particularly do this a lot to reduce quality so people aren't trying to watch 4k streams on a phone just because they can, it'll negotiate them down to what they feel is an acceptable like 480p, usually with some clause hidden in the fine print of your contract about acceptable use.
4K 직캠 will cost you extra
>To watch 1080p video on Naver or Afreeca, you have to install the p2p grid extension. so they can save on tariffs

1080p too huh
sounds like it will all be over soon cant imagine youtube's networth traffic bill
I'm sure they will make exception for youtube because it's too popular
tbh I can't see much sense in classical "l00d cover dancers" given how lewd aespa's and gidle's performances have become
think it's a proximity thing
aespa and gidle have https://www.youtube.com/watch?v=gfk3QLU1x0E to do with their time but you can see your streamer likely on schedule close up and responding (if you have a few bucks to send)
i presume of course
oh yeah, it's cheaper to have interaction with streamer than with the top idol
received monitor
which one
LG 27UP850

I have price alerts for LG 27GR93U-B and Gigabyte M28U right now
4k 144Hz, wish I knew what kind of colors to expect
can't stand my 2016 TN panel anymore, everything looks so washed out
set up second monitor. everything is so clean now and just two USB-C cables on the table (display inputs)
put logitech's dongle for mouse into first USB-A on the back of the monitor and screen light >>999930 into second USB-A, and hide extra cables in monitor arm's cable management container. works as I planned
also received notebook's stand today. now just need to wait few weeks
that China delivery is fucking slowuntil my new keyboard (mx keys mini) arrives and 2024-ready deck setup will be completed maybe will buy thunderbolt hub next year to make it 1 cable solution, but not strictly necessarythe only cons are: had to fix that thing >>997402 with a fucking pile because stupid gooks at LG made too tiny VESA mount and it couldn't fit and the whole thing is bit wobbly but I kinda knew it would be like that. seems like no real way around unless you make custom arm yourself. and even then will be wobbly anyway because physics
oh yeah. I had an option to buy 4K TN many years ago, but decided to go with 2.5K IPS Dell instead because it's properly calibrated, nice sRGB/Adobe RGB colorspace coverage, etc. unfortunately 2.5K doesn't work good on macOS, so now had to buy 4K, finally. also didn't want to go with cheap TN, the monitor + delivery was ~$500, a bit expensive for me, but welp
and the display on macbook is even better then both of them combined I'm not picky but it seems hard to find cheaper yet acceptable option: it's either too shitty or too premium
also tested here https://www.eizo.be/monitor-test/ and didn't notice any broken pixels, everything seems great, and picture quality is beautiful because returning heavy thing overseas would have been a real hassle
I'm only a bit afraid of the USB-C input port longevity because read about 5 posts where people were complaining it stopped working for them
now need get used to the new way of interacting with the screens
also bought 2x4TB expansion drives for my NAS (first for 4TB additional space, second for how swap)
thought about putting cache SSD into RAID-1 but dunno, seems not that necessary if you have backups, because at max you can only lose 1 day of work and restoring everything seems easy enough (unlike with main HDD array)
now only need to return that mx master mouse which I didn't like. I knew I shouldn't have received it, but decided to suffer anyway...

>lg $700
rich chingu
>wish I knew what kind of colors to expect
the matrix seems very similar to the one I have: IPS, 163 PPI, 100% sRGB, 95% DCI-P3, pseudo-HDR, 400 brightness
don't know much about monitors, but could be same just with better technology for refresh rate
>Both model specs are the same except USB Type C power delivery.
>27UP850 (96W), 27UP850N (90W).
I got the one with 90W
I knew all can't be that good

>rich chingu
the pricinfg for that one is weird, it's been down to almost 500€ before here
but yeah I want to get a nice monitor this time, gonna decide on it first before choosing any specs for the PC
rip
>gonna decide on it first before choosing any specs for the PC
planning to game on 4K@144Hz? rich chingu
I don't even care about 120Hz, 60Hz is fine
>down to almost 500€
oh, that's better. I would have bought it if needed more Hz
>planning to game on 4K@144Hz? rich chingu
I actually never minded turning down the settings, it shouldn't be a problem but I'll check some benchmarks
want it to be great outside of games too, since that's only like a portion of what I'll use it for
>rip
thunderbolt dock with 140w output is inevitable now
>since that's only like a portion of what I'll use it for
where would you need more Hz except gaming?
>where would you need more Hz except gaming?
need is a big word
but yeah I'll be gaming so I wouldn't settle for 60Hz

>I don't even care about 120Hz, 60Hz is fine
finally someone like me
in fact i can't even see any difference. i had a fancy 144hz gsynced monitor for a some years but didn't get it comparing between 144 and 60
I have 120Hz on macbook but web pages look weird sometimes, like lagging a bit when you scroll
I assume because it's dynamic refresh rate, it goes from 120Hz to 90Hz and vice versa all the time, so I believe it might be worse than stable 60Hz
tho I'm not sure, could be anything else, didn't investigate much
especially in fast paced games how clear moving stuff looks is a huge difference
I've been pretty competitive in shooters though, otherwise I could probably live without it too
Chrome deletes history older than 90 days
AND
it's excluded from backup (which I have)
RIP
monitors actually hiss if you put hear close enough
never noticed but once I started to look into monitors now I try to hear it at normal distance, especially when it's complete silence around like in the night
not sure if I really hear it (from normal distance) or it's my imagination, but seems like you can a bit
I moved my PC to another room to not hear anything and now noise-nim trying to fuck me up again
won't be an issue in 5 years anyway tho because I won't hear high frequencies as good
my 32" lg is silent even if i put my ear right to it
i do remember some electronic device of mine hissing but can't remember which so might be normal
>my 32" lg is silent even if i put my ear right to it
both my Dell and LG hiss
but macbook's display is silent
do you have 120V or 220V voltage at home?

i think that's a setting
ios safari however...
>i think that's a setting
nah
they just delete your history. the only way around is to use third-party plugin which will save it in other place
>it's real
what the heck, when did that happen
i don't use chrome that much so i didn't realize
i guess it's at least better than safari's 1 month history
>what the heck, when did that happen
1-2 years I think. it was due to users with shitty computers/websites which pollute history so it slows down things or something like that
>i don't use chrome that much
firefox?
safari is shitty browser tbh, I couldn't use it even tho it integrates in the system better
oh no, with multiple monitors the macos's retardness "no clicks in non-focused windows" is even worse
>macOS windows requiring an explicit click to make active, before UI elements inside can be clicked
what a weird thingy
kinda funny how windows and chromeos even have extremely comfy 1/3, 2/3 window splits built-in, while macos keeps going the way of ios with the funny full screen meme that take 2 seconds to animate
windows really is the only sensible os that works without pain, but it's future is very unclear
i'd like to move to chromeos but scroll wheel works the same as macos (=doesn't work ) plus mpv is kinda meh
>windows and chromeos even have extremely comfy 1/3, 2/3 window splits built-in
fortunately it's not hard to fix by installing nice tiny 3rd party app
but the clicky thing is more complex
also it was hard to make switch between 3 languages work conveniently, had to modify open source app for that
>windows really is the only sensible os that works without pain
dunno, it has its own retardness, like WSL drives being mounted through brittle virtual file systems (though if you use docker in macos it's the same), and the architecture with all its legacy being a total mess. but a bit better than macOS overall I think
>it's future is very unclear
>mpv is kinda meh
what do you mean?
>like WSL drives
haven't faced brittleness but you'd probably have your source code uploaded to some remote anyway
>what do you mean?
can't drag&drop videos/links (probably some x11 app interaction limitation).
can't copypaste videos (apps cant read clipboard on chromeos, would have to paste the link to some form input instead probably).
apps can't access filesystem willy nilly so mpv can't read the subtitle file next to the video file
>so mpv can't read the subtitle file next to the video file
but can access HTTP?
what if you make HTTP proxy API for the file system
>source code uploaded to some remote anyway
yeah file access inside VM's VDI is fine, but sometimes you want to interact with host's NTFS and it isn't always great experience
but they probably make it better overtime
why would you use chromeos anyway, I've never yet met a person who uses it
do you just have free chromebook from your uni laying around?
scared of apps looking through my stuff on windows an exe can read absolutely everything from the file system, my keystrokes and anything i have open
probably autism, normal people have all sorts of weird applications installed and are still alive
>Microsoft readies 'groundbreaking' AI-focused Windows release as new leadership takes the helm
oh yeah, it's a problem humanity don't even know how to solve yet
you can find all sorts of "production-ready" solutions like SELinux, Qubes OS, SliverBlue, etc, but the reality is they would never work for 100% of people
so yeah, we basically at "not significant enough for target attack" state now
>scared of apps looking through my stuff
but I meant only allow it to go through /media dir
I have DLNA server on my NAS, it's allowed to read all my media files but it's fine because there is no private stuff there
except my porn favours
>don't even know how to solve yet
unless all apps are web apps it's just that theres no vidya player web app like mpv yet
>all apps are web apps
well it's kinda solved on ios by: all apps only through AppStore and containerization (though there're still system-level vulns possible and you can allow some app access all your photos and it may turn to be malicious (which will be removed but the damage already done))
but we can't use ios-like OS to make real work. yet.
same with macos appstore apps though right? so everything other than the random binaries from github you need to make macos kind of usable
>same with macos appstore apps though right?
there's some containerization but afaik it's optional
and anyway, the access perms aren't granular enough. it just asks "allow access to Documents" and it can access ALL your documents
and you can do a lot of damage even without that access. so it just helps "a bit" at most
>the random binaries from github
lol. I would say 50% of all big apps are installed through .dmg, not via AppStore
like Discord and Chrome for example
>I would say 50% of all big apps
maybe even more
think about Microsoft Store on Windows, in my experience about same level of popularity
>so it just helps "a bit" at most
and creates tons of trouble for people who are trying to use some automatization tasks via Shortcuts or something like that
so that's why I said nobody knows how to solve it
fuck, with HiDPI monitor the kch's icon now looks pixelated because it's only 16x16
>trouble for people who are trying to use some automatization tasks via Shortcuts or something like that
oh yeah i guess trust is the only option
i currently have 12 applications installed can i trust them
disc*rd definitely reads all my window titles and reports them to the mothership dont they
>i guess trust is the only option
I was more focused on security when I was younger but now I became relaxed a bit. and I read tons of stories like that (not always, but seems like a trend)
so enjoy being nerd while you can
why scroll wheel up do the zoom in
it's not only on kch, same in chrome's pdf viewer
tho in other app I have it's scroll wheel down to zoom in
https://www.reddit.com/r/cad/comments/pebw8g/zooming_in_mouse_wheel_up_or_down/
>Especially if you use a 3D mouse it's a lot more natural to think of your controls as manipulating the object, not the camera. It's not zooming in, it's pulling closer.
makes sense, especially if you’re used to touchpad
sold mouse just after few days for even a bit higher price than I’ve bought it
and seller said he will gift me $10 just because they don’t like to deal with returns
can’t all be this good, something bad should happen, right?
and it did, I got sick
it's trust all the way down
https://www.cs.cmu.edu/~rdriley/487/papers/Thompson_1984_ReflectionsonTrustingTrust.pdf
oh I read that paper
wtf, some 60% keyboards actually have arrow keys
https://www.reddit.com/r/logitech/comments/rg2x02/logi_options_beta_uninstaller_in_mac_os_missing/
logitech's software is a joke
they really tell users to uninstall app from command line
somebody at logitech doesn't want to admit the optimal way to use their software is to set your stuff then uninstall
is it profitable to make bloatware? won't tiny fast app make customers happier?
or normies don't care?
>I don't think it's an accident that the older Logitech software (written in C++) all still works fine, but the new shit written in JavaScript as Electron apps is broken, bloated, and less than useless. Yet another company tried to save money by hiring cheaper devs and reusing (broken) code on multiple OS platforms rather than just paying someone competent to do it right the first time.
>or normies don't care?
they'll have the same shitty expereince but won't have any idea what the problem is
what it do
at least g305 has few enough buttons to not need additional software
I still want a new nice gaming mouse even though my current one works, I'm a bit tired of it
g502 and g pro look pretty nice
I had to adjust the DPI when I first got it. but it remembers it just fine
will be pain if you want to adjust something again tho
I use G Pro superlight and love it
most people recommend smaller mice for better aiming
thanks, looks nice and only a bit more expensive than the mx master 3s
oh no, I might impulsive buy it right away
the only cons is that it comes with LightSpeed receiver but MX Keys Mini works only with Bolt. I'm afraid bluetooth keyboard might have a bit of latency, so it would require 2 different dongles
>smaller mice
I have AAA li-ion battery mod on my G305, feels nice
makes you think, can you actually adapt to big mouses after using a small one for a long time? as far as I can remember, I always had small to mid-sized mouses. but maybe big ones would work fine too?
do you have mouse pad?


>the only cons is that it comes with LightSpeed receiver but MX Keys Mini works only with Bolt
that's annoying, could use a small USB splitter though if you have to
yeah lol, one of those massive ones
Rina
do you have the superlight 1 or superlight 2?
1, with the micro USB unfortunatly
it also uses optical switches so probably less prone to double clicking
a bit expensive tho
the mouse settings in the macos are so complicated
I regret I started looking into that stuff
first we have speed of the cursor and the new setting "disable pointer acceleration" in new macos
then there's also "disable mouse acceleration" setting in UnnaturalScrollWheels
then there're DPI settings for the mouse
disable pointer acceleration and disable mouse acceleration work differently. I dunno that are they both doing
speed of the cursor is probably multiplied by DPI of the mouse. but I dunno, should I set very high speed and small DPI or very high DPI and small speed? and high DPI probably drains battery a bit faster
people say it's better to disable pointer acceleration to have consistent movement, I've tried it and it's a bit weird feeling. but maybe I should get used to it. also with disable mouse acceleration I need to use much smaller DPI, and with enabled much higher. like 800 DPI if enabled, 3200 if disabled. what's better?
it's all so tiresome
>800 DPI if enabled, 3200 if disabled
vice versa
also, it seems like mouse acceleration really helps to click the small UI elements (like resize the tiny border of kch's reply form)
so dunno, maybe the problem is the fast speed of the cursor (which is multiplied by DPI)? or I should just leave the acceleration enabled?
>the problem is the fast speed of the cursor
or seems like it's just the way linear scale works
if you have big display, like 3840x2160, you want to spend less time moving cursor from one corner to another, so you have high DPI
but then you also want to move mouse by 1px inside that same display but the cursor will move very fast so it's hard
personally the first thing I do on any PC I'm on is turn the mouse acceleration off
I can't deal with it but it's just because I'm used to it, might be the opposite for you
I've spent some time comparing "acceleration off + 800 DPI" and "acceleration on + 3200 DPI" which give about the same speed of the cursor movement and I'm definitely more precise with small UI elements with the latter
maybe it's just a way it's implemented in macOS tho
also, I think I've had something different than 3200 before and I messed it up when started experimenting so now it feels different anyway than what I've been using for many years

also the cursor speed slider changes the
com.apple.mouse.scalinginternal setting, possible values on the picscaling=1 seems like the most sane thing? like don't change anything what's coming from the hardware
https://github.com/apsun/NoMouseAccel/blob/master/NoMouseAccel/main.c
>As it turns out, this works due to a... bug? feature? in IOHIDFamily/IOHIDEventSystemPlugIns/IOHIDPointerScrollFilter.cpp. The acceleration is reset, then the new acceleration is checked for a negative value. If it is negative, the function immediately returns without configuring a new acceleration value, which gives us the "unaccelerated" behavior.
some hack

i just use winodws default its nice
and after getting g305 kde default works too just just press the pointer speed button in the mouse itself a different amount of times and boom, feels the same as windows
the default DPIs are 400 800 1600 3200, but I'm trying 2400 now
though I think I can live with 3200 and smaller scaling >>1001105 too
>400 800 1600 3200
you mean in g305?
why are the speeds different in different OS then? acceleration curve not being the same?
>you mean in g305?
yes
>acceleration curve not being the same?
yeah, probably
which DPI do you use btw? it goes from 400 to 3200 when you click the button on the mouse
1600
3200 + scaling=1 seems ok
1600 + scaling=3 is still too slow
so dunno what DPI I've had before because I had scaling=3
maybe it was 1600 tho but I confused myself when was trying different DPIs
how do i avoid pizza burning my mouth

give it to isa
>Congrats! You’re in. You can start using v0 to generate your own UI.
>Each generation costs 10 credits, except for the first generation which costs 30 credits (as it results in three generations).
>You have 1200 credits left
so just 40-120 prompts
https://www.youtube.com/watch?v=6gYVGUBOsvA
what grip do you use?
for me a combination of fingertip/palm seems to be working the best
though if you think about it
people in shooters do the task of aiming the opponent and killing it as fast and as precise as they can
isn't it better to use AI to aim and kill 1000x faster? it's like playing chess when computers do it much better
yeah same
that would be cheating I'm pretty sure
chromeos is best here, just install keyboards and swap between languages, and when korean swap between english and korean, bim bam boom
windows is okayish, same install and swappy swappy, except when korean each app has its own english/korean state that you would have to remember (how on earth would you remember) that also on some apps changes by itself plus the indicator in taskbar is always wrong or late
kde has all the options to make it work however you want so swap between languages, don't need the english/korean miniswap thing if you don't want either. but the setup is a lot more work you don't install keyboards you have to install korean as a motherhecking device with some funny console magic to get the right programs in also
wouldn't it be easier to use the korean keyboard all the time?
it's basically english with an extra layer
couple special characters i think that are in different keys between us ansi and korean ansi
but other than that i guess i could (on chromeos not on windows though with the sad situation )
I use this bad boy
US layout with äëöüß and euro sign in the right Alt layer
>iso layout
I would never, but gnome has no idea
https://www.youtube.com/watch?v=kQpqPeZCq7c
can humanity invent something more attractive than east-asian cute/sekshie idols? (maybe with the help of AI-powered search)
or we achieved the best possible form for the unmodified brain?
iso
i read recently the polish iso keyboard was so dog dumb that everyone switched to ansi
>that would be cheating I'm pretty sure
I mean what's the point of mastering skills in the task that can be done much better by the computer
as an example:
- building more powerful AI: makes sense, computer can't do that by themselves yet
- playing chess: makes little sense, you will never be better than computer
of course a lot of people still play chess so it's a complicated question
its a game yea consoles games do have auto aim if you are interested tho
the purpose of those things is more complex than simply winning
>chromeos is best here, just install keyboards and swap between languages, and when korean swap between english and korean, bim bam boom
>windows is okayish, same install and swappy swappy, except when korean each app has its own english/korean state that you would have to
you mean you have two shortcuts:
- switch between your local language and korean
- switch between korean and english in korean layout
I had that in Windows, Alt+Shift for the first and Right Alt for the second but it wasn't very convenient either
now I have Alt+1, Alt+2, Alt+3 to shift between three languages and also Ctrl+Space to shift between current and previous language
so for example you was on English, then you switch to Korean with Alt+3, and if you press Ctrl+Space it switches back to English. so it's convenient to both switch to e.g. Korean when you're suddenly in a mood of writing some Korean. and to quickly switch between current and previous language when you write in local language but need to use a lot of English words
the downside is that you have different type of hotkeys for the same thing (switching languages). also it doesn't work that way on macos it seems. only korean letters in korean layout
sounds comfy could probably make kde work that way
>switch between korean and english in korean layout
yeah
idk why the hangul/english switch has to be so garbage
in fact theres a setting in windows to enable app specific languages, imagine trying to remember what language each app was on and then if in korean whether it was in english or korean
>quickly switch between current and previous language
i think chrome worked this way (plus different shortcut for cycle between all) its really more comfy since you don't constantly need the third language
>in fact theres a setting in windows to enable app specific languages
yeah, I always disable that
also I always switch back to English if I don't need other languages in 5 nearest seconds it's a bit of OCD thing, maybe I should find an app which does that for me
>since you don't constantly need the third language
yeah
things are a bit tricky when you type in 3 languages at once tho too many switches per minute
like when you do Markdown notes on Korean language with explanations in your local language, you need all three
https://www.youtube.com/watch?v=QUNrBEhvXWQ
>how search works so fast
>uh it's many many computers so it's faster, okay?
fucking idiot has no idea he's talking about
for me it's the opposite: seeking in VP9 stream with mpv rarely works, but with H.264 it's fine
https://www.youtube.com/watch?v=I19btmIBhx0
japanese hikikomoris were the early adopters?
what a weird os
recovered a very cute deleted image from the redreader cache
bless them for telling you the cache path in settings
post it
no it's mine and mine alone now
not kpop though so don't worry
>compressed towel tablets
what's the most fun way to transfer some terabytes of files from a ntfs external disk to an apfs external disk?
rsync -ah --info=progress2 /mnt/disk1/ /mnt/disk2/

rsync AH
oh macbooks can read ntfs
yeah, only in read-only mode tho
amazing
새로운 스레드 언제지?
https://www.youtube.com/watch?v=xUT4d5IVY0A
I bet this presentation was made by one of those "diversity hires"
why can't americans stop destroying themselves

>stay awake for 34 hours to fix sleep schedule
>can't sleep now
wtf
I try to fix schedule by keeping alarm at 10am for months now, but I mechanically turn it off and just sleep for few more hours anyway
maybe need to try with 12pm instead

is there like a winget thing for macos (install precompiled binaries thingymagic) instead of this macports type install from source it takes a million years to install anything and it's dependencies
brew? bottles are precompiled, if you don't need custom flags/git master

sounds like winget thanks
I surprised you knew about macports, but didn't about brew

i thought it only had caskets for precompiled (plus gui only)
https://www.youtube.com/watch?v=unMXQTSQEak
>I'm down to 8 keys. I just memorized the whole UTF-8 Unicode Encoding and insert the bytes I need with each finger being a bit.
https://github.com/Homebrew/homebrew-cask/blob/master/Casks/m/mpv.rb>stolendata.net
those are x64 builds, better compile mpv from sources on arm mac
but all other dependencies (such as ffmpeg) would be precompiled (and for arm ISA) which is fine
or you can use the formula (without app) https://github.com/Homebrew/homebrew-core/blob/master/Formula/m/mpv.rb
there are precompiled bottles
you can do an app with AppleScript, I can post you example if you need it
this will allow to open multiple files from Finder. the default app can only do one window so you can open only one file simultaneously
>I'm still wondering how would I use this with Blender or any other software with a lot of key combinations.
>response1: it's not much different, but key combinations are all easier to hit
>response2: I haven't had any weird key combo like that, but if it comes up, you can also add mods to your symbol layer
>response3: I guess you could get another smaller and simpler keyboard and assign those weird key combinations to its keys
the absolute state of custom layout retards
first they say it works perfectly good for any task
then they say your task is weird, but you can always modify the config
then they say your task is stupid, so go buy another keyboard because their perfect layout which is suitable for everyone won't work
I can't believe people can be this delusional, but they are
>this will allow to open multiple files from Finder. the default app can only do one window so you can open only one file simultaneously
oh thanks post example if you have
basically this https://github.com/mpv-player/mpv/issues/1377#issuecomment-1653713152
for mpv binary from formula (without app) the one below: https://github.com/mpv-player/mpv/issues/1377#issuecomment-1751510069
https://news.ycombinator.com/item?id=27421028
>In addition to being able to run QMK on a keyboard, you could also get a macropad, or just a second keyboard
lol reminds me those linux fanatics
well it's just the same pattern of finding a solution for non-existing problems anyway
it works fancy as heck
do you have macbook too? which one?
https://www.youtube.com/watch?v=JsRTTD9k2ME
can you stenography korean though they speak insanely fast

>As the results for young adults who speak Korean standard language (Seoul speech), averaged speech rates for male speakers were 334.2 spm and those for female speakers were 314.4 spm. In this study, the averaged conversational speech rate for male speakers was 356.4 spm and that for female speakers was 330.2 spm.
https://www.reddit.com/r/Korean/comments/12ugzf0/do_koreans_tend_to_talk_really_fast/
>I did hear that languages in general communicate information at roughly the same rate. So languages with longer words speak faster than languages with short words.
>Faster than your average English speaker
we can measure the entropy of the information flow of different nations/races
https://www.science.org/doi/10.1126/sciadv.aaw2594
>fast speakers are likely to produce less informative content
so those 빨리 빨리 koreans are just showing off
all their fast speeches actually contain to useful additional information, just trying to looking good in eyes of the manager-nims
only making life harder for us, filthy 외퀴s
>In parallel, from independently available written corpora in these languages, we estimated each language’s information density (ID) as the syllable conditional entropy to take word-internal syllable-bigram dependencies into account.
how do you calculate ID from a text in a language?

Korean is about the same SR as Spanish and Finnish? interesting
I only heard about Italian being fast
>They found that Japanese, which has only 643 syllables, had an information density of about 5 bits per syllable, whereas English, with its 6949 syllables, had a density of just over 7 bits per syllable. Vietnamese, with its complex system of six tones (each of which can further differentiate a syllable), topped the charts at 8 bits per syllable.
how do you calculate that
stupid "science" papers explaining nothing useful

https://www.science.org/doi/10.1126/sciadv.aaw2594#:~:text=For%20each%20language%20L
found
so basically entropy of the language depends on how many syllables are and how often they appear in any given text
assuming texts in general transmit about the same amount in information

>We found that IR is centered on a mean of 39.15 bits/s
English and French look more dense to me. why didn't they say about this, political correctness?
anyway, fast speaking Koreans are scientifically pwned now
https://www.science.org/doi/suppl/10.1126/sciadv.aaw2594/suppl_file/aaw2594_sm.pdf
I looked into the text they gave to native speakers to read
in Korean it's formal polite style with tons of 습니다 십시오 and other useless stuff in every sentence
no wonder Korean got such a low ID
in other words this metric >>1002764 is completely useless
it only counts the probabilities of 습, 니, 다 separately, but doesn't account at all how often 다 comes after 니 after 습 which is obviously very often
shitty paper, so the results are useless

>finally get to sleep
>wake up the usual time
it was all for nothing
Gong!
https://www.youtube.com/watch?v=3jPKtQIto2c
looks much more useful than those dumb 34 key layouts which provide absolutely no value
at least with steno you can type fast

>In order to pass the United States Registered Professional Reporter test, a trained court reporter or closed captioner must write speeds of approximately 180, 200, and 225 words per minute (wpm) at very high accuracy in the categories of literary, jury charge, and testimony, respectively
maybe live subbers need steno writers

>live subbers
should be replaced by AI at this point tho
that stupid website works badly, course isn't moving fast enough, so I make more mistakes
it's over, I can't beat it
I'm the worst

when the twitch news came i checked out some lives and they have em openai whispers running on the screen
maybe not too accurate yet but helps eng watchers know what them talking about

why even learn anything at this point if AI will crush you in few years

yeah
i didn't actually believe it until i saw this maym image
its real, and its officially over

want to beat me in korean touch typing?
I'm very bad at it too tho

not that bad anymore

hard to not get mixed up writing korean even after 2 years or how ever many old is the other thread
I remembered the layout, but basically never trained it since then so have a lot of issues with ㅈㄷㅌㅊ (especially because for some stupid reason they are in different order on top and on the bottom)
and the letter that triggers me the most is ㅂ/ㅁ because ㅂ니다 sounds like ㅁ니다 so my brain confused sound/writing/typing neural signals and I type it wrong very often
but because I not type a lot of korean that speed is kinda sufficient anyway

>they are in different order on top and on the bottom
this is the funniest part why is the order the complete opposite??
maybe that's in google somewhere but I can only rationalize the creator thought it's better for muscle memory to go in zigzag than in straight line
or maybe related to typing frequency but that's unlikely
https://korean.stackexchange.com/q/6025
yeah, people agree it's some typical gook stupidity for no reason
>they focused more on the ease of learning than on the frequency
https://namu.wiki/w/QWER?from=ㅂㅈㄷㄱ lol
they navigate you to magenta when you read about keyboards

>163cm|45kg|A형|245mm|75C
https://theme.archives.go.kr/viewer/common/archWebViewer.do?singleData=Y&archiveEventId=0049290277
is that it?
ㄱ > ㄷ > ㅈ > ㅂ > ㅊ > ㅍ > ㅌ > ㅋ
so in their frequency analysis ㄱ for the point finger and ㅋ for the pinky finger makes sense, and everything else was mirrored for consistency
need smart nim to read that ancient handwritten gook text in detail
in this guy's analysis from stackexchange https://pastebin.com/rEF8QxiZ it's
ㄱ > ㄷ > ㅈ > ㅂ > ㅊ > ㅌ > ㅍ > ㅋ
which is basically the same, with only single difference
so in my understanding the gooks saw the correlation here, with just ㅍ being out of the order
but I would still prefer ㅂㅈㄷㄱ ㅍㅊㅌㅋ just for the ease of learning


YEEEEEEEEEEEEEEEEEEEEEES
hahahhahahahahah
I beat you!!!!!!

sorry i took a course
in middle school
wait 112 be right back

try this
nooooooooooooooooooooo
how did you make it so fast
also you probably use some fancy mechanical keyboard and I'm on default notebook's one
>i took a course
I studied through a good program, but only my local language. never studied english properly, but when you know one layout, everything else is kinda the same rules anyway
still, when you study specific language like english you will probably get better results tho

I'm getting closer
although if you think about it a bit more it could have been:
ㅋㅊㅈㄱ
ㅁㄴㅇㄹ
ㅌㅍㅂㄷ
pointer finger goes to ㄱㄷ, middle to ㅈㅂ, ring to ㅊㅍ, pinky to ㅋㅌ
instead they put both ㅂ and ㅋ to pinky although ㅂ is much more frequent than ㅋ

this is on an external apple keyboard
very unused to it by now thodid you know mac keyboards have extremely small travel while still clicky so they could theoretically be much faster to write on than mechanicalalthough i'm on slim mechanical so not super long travel either
>mac keyboards have extremely small travel while still clicky so they could theoretically be much faster to write on than mechanical
yeah, I think that too
just tried to put pressure on you
do you have macbook or what? 빨리 대답!
yeah i did
by the end the usb-c port started to glitch >>1000374
>I'm only a bit afraid of the USB-C input port longevity
be very afraid
I meant the USB-C port with PD on the display, people reported it stopped outputting power to the macbook after some time
btw, noticed one issue with that port
when I turn my displays off before going to bed, it stops outputting power too, so macbook is on battery for the whole night. probably not a big deal but still a bit worried about the battery longevity. or maybe it's even a bit better than always keep it charged? not sure
many shouldn't turn displays off at all, but then they might sometimes turn on during night because mouse glitched and moved a bit
>many shouldn't turn
maybe*
>yeah i did
you had macbook but now don't? where do you attach apple keyboard to
>i'm on slim mechanical
which one
yeah it does
the lg i have also sometimes doesnt connect usb-c after booting up you need to power cycle the monitor
https://mactrovert.com/lg-32un880-b-display-issues-with-m1-mac-mini-when-using-usb-c/it would be cool to have a mini pc without a power adapter just a usb-c for power+display, but obviously doesn't work with this since you can't turn off the monitor and sometimes need to power cycle it anyway
i sold it but didn't sell the apple keyboard so its in my closet
https://www.havit.hk/products/havithv-kb390l-low-profile-mechanical-switches-backlit-keyboard/
>but obviously doesn't work with this since you can't turn off the monitor and sometimes need to power cycle it anyway
makes me think why didn't they make separate power off button for the power for USB-C
>i sold it
how do you use macos then? hackintosh or another mac?
>because mouse glitched and moved a bit
or maybe can just turn off the mouse
https://www.youtube.com/watch?v=e1cf58VWzt8
>you are purely for-profit and controlled by microsoft
>we are not purely for-profit and we aren't controlled by microsoft
https://www.reddit.com/r/youtube/comments/17vrypg/the_youtube_comment_section_has_become_absolutely/
>But you're right--the effusive praise, with lack of any other substantive commentary, is all over the comments of every worthwhile video.
there has never been anything worth reading in there afaik
sometimes there are useful comments but it's hard to find them, have to scroll a lot
also where else would you go if you want some additional thoughts on the ideas in the video
repost video to reddit and wait for answers? waste of time
k-comments on kpop videos can be fun but finding kernel experts on youtube might not be the easiest tasks